Tracing Multiple Agents
When working with AI-powered workflows, efficiency, scalability, and cost control are. In many scenarios, a single-agent architecture often fails to meet all operational requirements, leading developers to adopt multi-agent workflows.
LangDB simplifies this by offering seamless tracing, analytics, and optimization tools for multi-agent workflows.
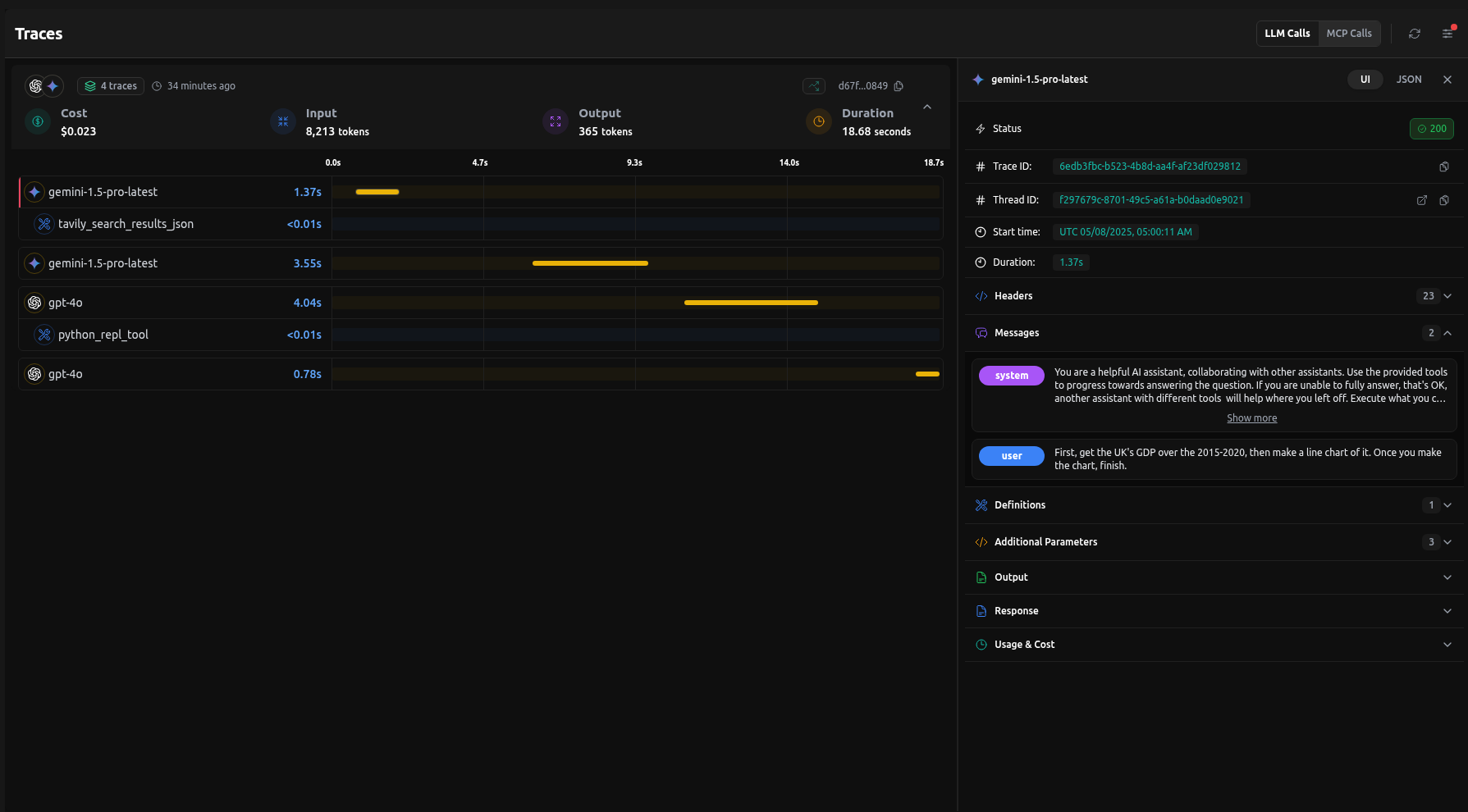
TLDR, Combining Gemini and GPT offers lower costs, though it’s slightly slower than using a single model.
| Tag | Total Cost | Total Requests | Avg Duration (ms) | Total Duration (ms) | Total Input Tokens | Total Output Tokens | Avg TTFT (ms) | TPS | TPOT |
|---|---|---|---|---|---|---|---|---|---|
| [gemini] | 0.037731 | 4 | 2390.0 | 9559.802 | 11197 | 345 | 2390.0 | 1207.35 | 0.03 |
| [gpt-4o] | 0.057021 | 4 | 4574.9 | 18299.686 | 17235 | 443 | 4574.9 | 966.03 | 0.04 |
| [combined] | 0.034887 | 4 | 2765.5 | 11061.997 | 10009 | 405 | 2765.5 | 941.42 | 0.03 |
Let’s break down a typical multi-agent workflow:
Example: Generating a Chart for a given question
- User Request: "Generate a chart of average temperature in Alaska over the past decade."
- Agent Roles:
- Researcher Agent: Gathers raw temperature data by calling a search tool.
- Chart Generator Agent: Processes the data and creates a visualization using a code execution tool.
Here’s how this workflow is structured across multiple agents.
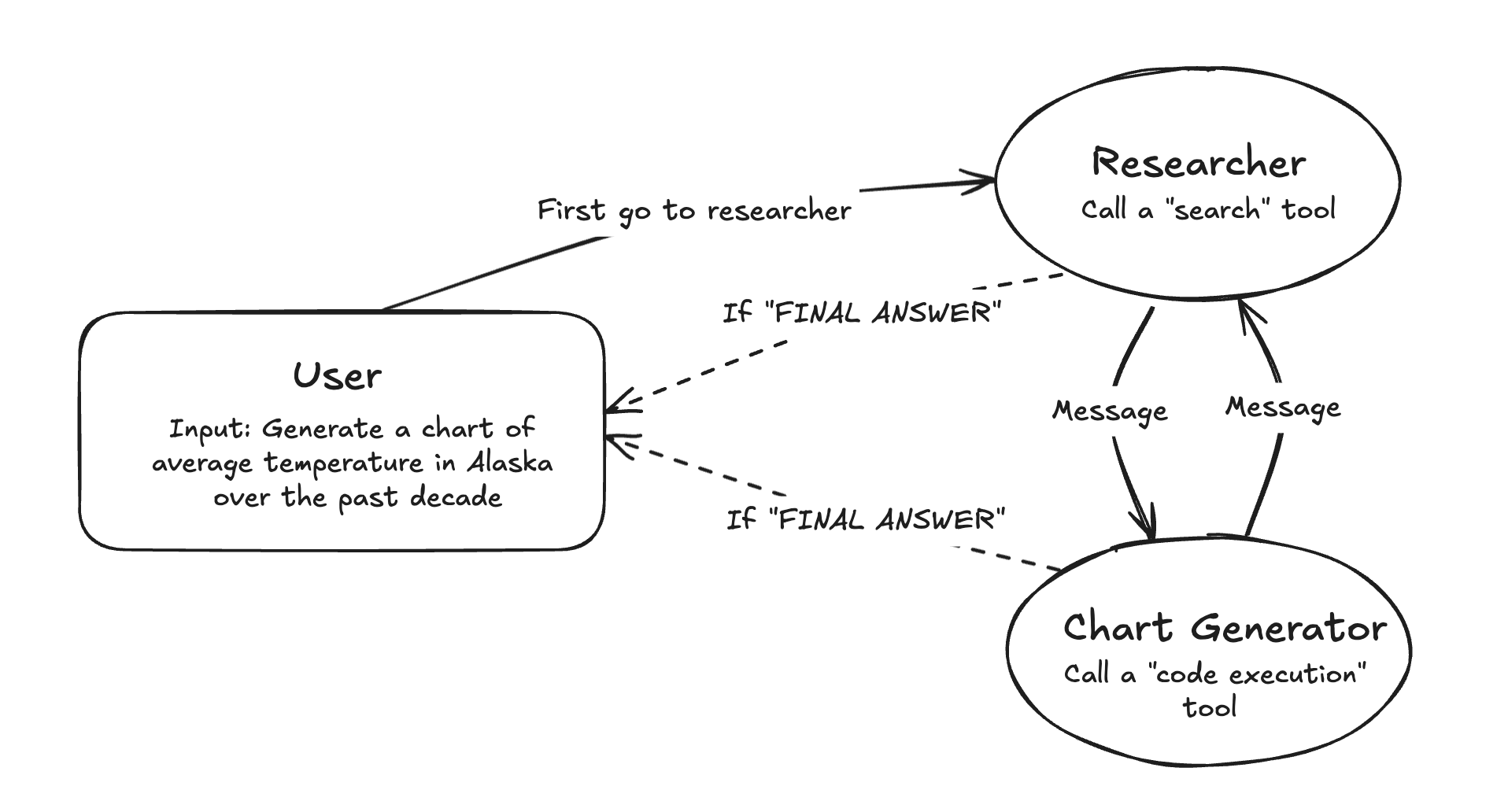
To evaluate the efficiency of multi-agent workflows, we ran three different setups in LangDB. These scenarios illustrate how using the same model across agents compares to combining models.
Scenarios We Tested
To evaluate the efficiency of multi-agent workflows, we tested three setups. In the first scenario, both the Researcher Agent and Chart Generator Agent used Gemini, focusing on speed and cost. In the second scenario, both agents used GPT-4o, prioritizing accuracy but incurring higher costs. Finally, in the third scenario, we combined models: the Researcher Agent used Gemini for data gathering, while the Chart Generator Agent used GPT-4o for visualization. This allowed us to balance speed, cost, and accuracy
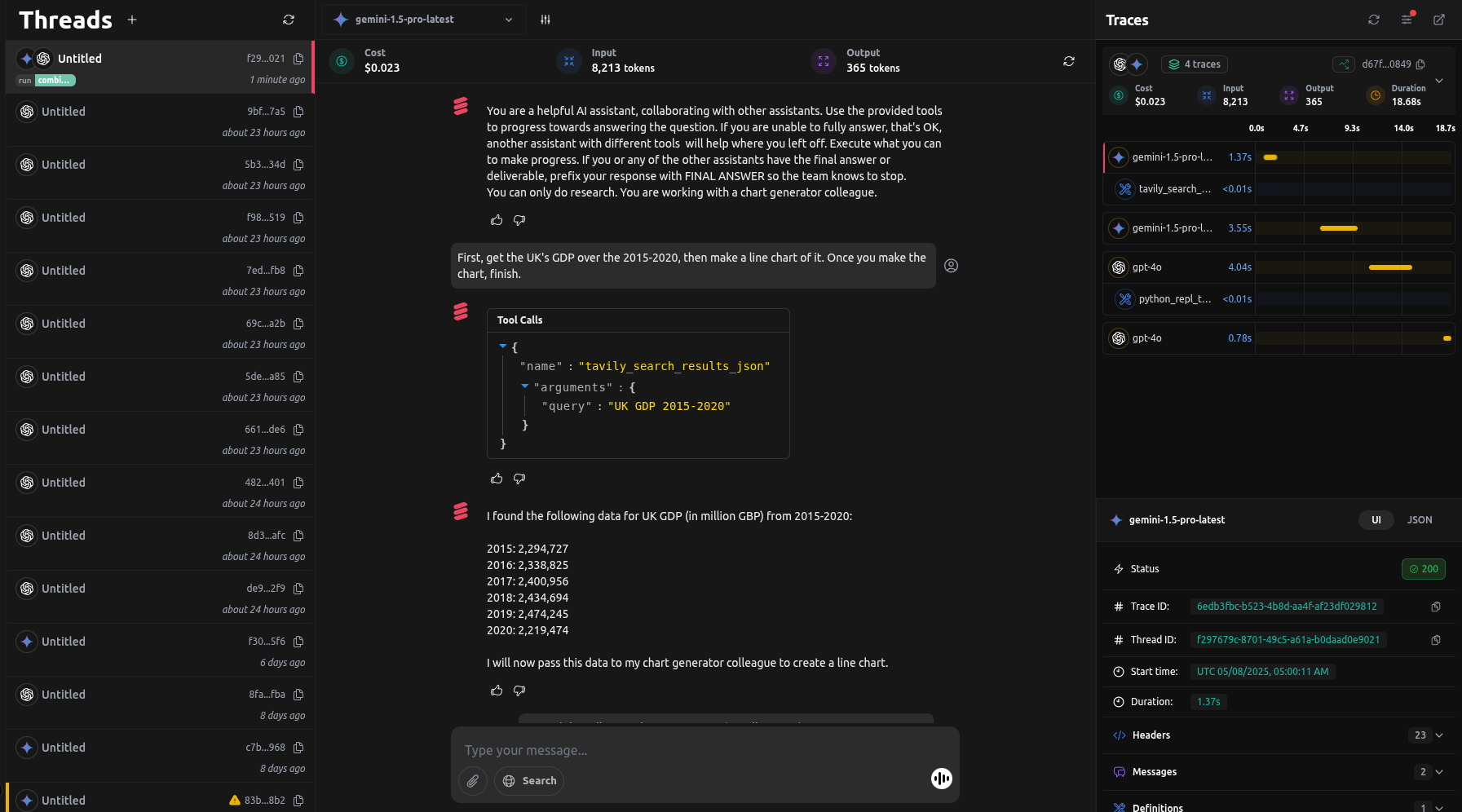
Tracing and Analytics with LangDB
After running these scenarios, we used LangDB's tracing capabilities to monitor task routing, response times, and token usage. The tracing interface allowed us to see exactly how tasks were distributed between agents and measure the efficiency of each workflow.
Using LangDB's analytics, we evaluated the performance data from these runs to generate the table presented earlier. This included:
- Cost Analysis: Tracking how much each agent contributed to the overall expense.
- Time Analysis: Measuring the average response time across different workflows.
- Number of Requests: Recording how many requests each run processed.
- Average Time to First Token (TTFT): Capturing the time taken for the first token to appear.
- Tokens Per Second (TPS): Analyzing the efficiency of token generation per second.
- Time Per Output Token (TPOT): Evaluating the time taken per output token to assess response efficiency.
| Tag | Total Cost | Total Requests | Avg Duration (ms) | Total Duration (ms) | Total Input Tokens | Total Output Tokens | Avg TTFT (ms) | TPS | TPOT |
|---|---|---|---|---|---|---|---|---|---|
| [gemini] | 0.037731 | 4 | 2390.0 | 9559.802 | 11197 | 345 | 2390.0 | 1207.35 | 0.03 |
| [gpt-4o] | 0.057021 | 4 | 4574.9 | 18299.686 | 17235 | 443 | 4574.9 | 966.03 | 0.04 |
| [combined] | 0.034887 | 4 | 2765.5 | 11061.997 | 10009 | 405 | 2765.5 | 941.42 | 0.03 |
Key Takeaways from the Scenarios
1. Gemini-Only Workflow
- Cost: Slightly higher than combined but cheaper than GPT-4o.
- Speed: Fastest average duration (2390 ms) and highest TPS (1207.35).
2. GPT-4o-Only Workflow
- Cost: Highest overall.
- Speed: Slowest duration (4574.9 ms) and lower TPS (966.03).
3. Combined Workflow
- Cost: Lowest of all workflows.
- Speed: Moderate duration (2765.5 ms) and TPS (941.42).
Why Tracing Matters for Multi-Agent Workflows
In a multi-agent workflow, different models handle specialized tasks. Without proper observability, you don't know how efficiently each model is performing. This lack of visibility can lead to:
- Escalating Costs: Premium models being overused for trivial tasks.
- Performance Bottlenecks: Delays caused by slow or inefficient task execution.
- Operational Inefficiency: No clear insights on how to optimize workflows.
Why LangDB is Essential for Multi-Agent Workflows
With LangDB, you can:
- Monitor Key Metrics: Track costs, latency, number of requests, and token usage for each workflow.
- Analyze Performance Trends: Understand response times, time to first token, and processing speeds across different models.
- Gain Detail Insights: Use detailed analytics to identify inefficiencies and optimize workflows accordingly.
Next Steps
To explore multi-agent workflows with LangDB:
- Visit the LangDB Samples Repository for setup instructions and examples.
- Try out LangDB to monitor and optimize your workflows in real time.
- Experiment with combining different models to achieve the best results for your unique use case.
Explore LangDB’s capabilities by visiting the LangDB Samples Repository or trying the platform for multi-agent tracing and analytics.