Building Reporting Writing Agent Using CrewAI
Build a powerful multi-agent report generation workflow with CrewAI and LangDB. This guide walks through the full setup: from configuring your agents to sharing a public execution trace.
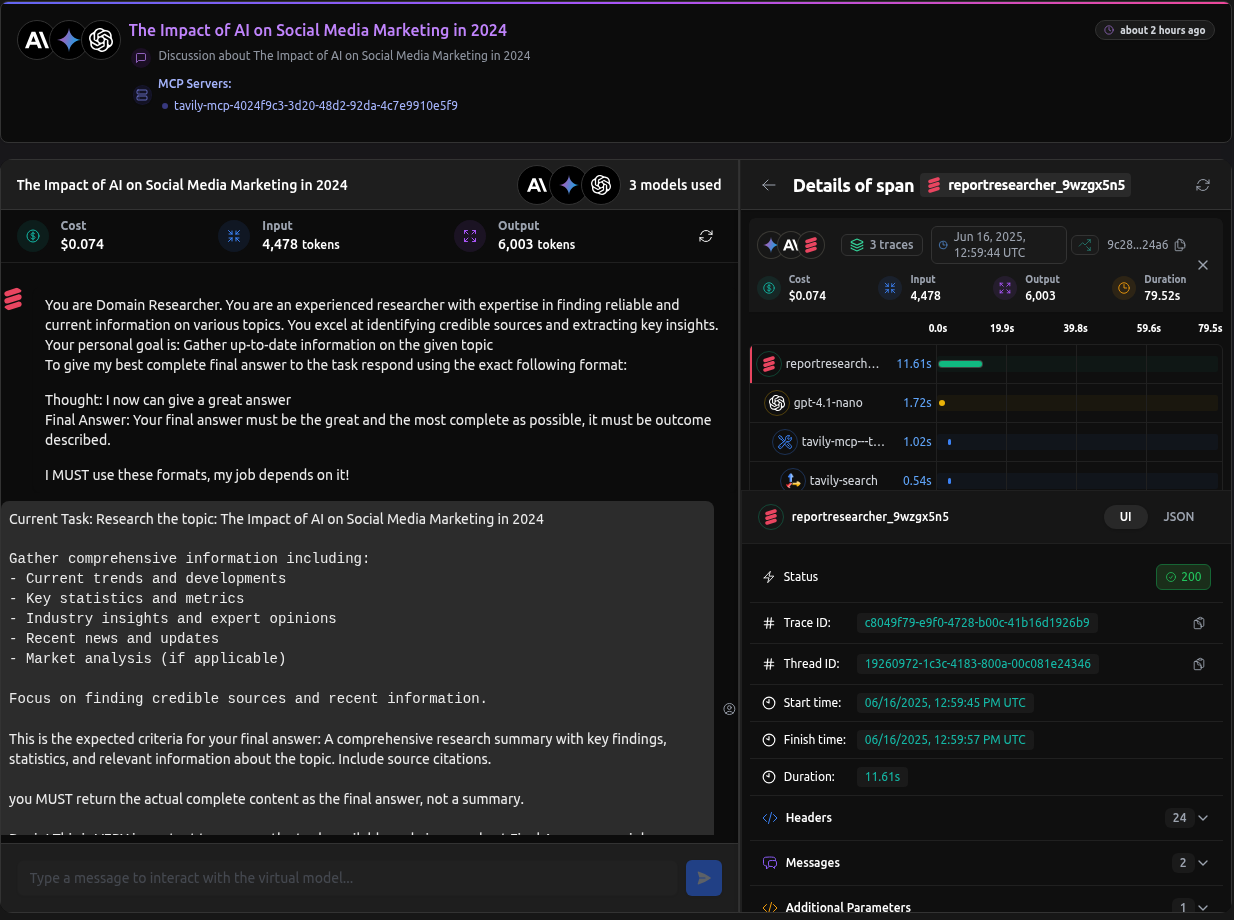
Checkout: https://app.langdb.ai/sharing/threads/3becbfed-a1be-ae84-ea3c-4942867a3e22
Code
- LangDB Samples: https://github.com/langdb/langdb-samples/tree/main/examples/crewai/report-writing-agent
Goal
Create a report-writing AI system where:
- A Researcher Agent gathers up-to-date information using web tools like Tavily Search.
- An Analyst Agent processes and synthesizes the findings.
- A Report Writer Agent generates a clean, markdown-formatted report.
LangDB enables seamless model routing, tracing, and observability across this pipeline, including full visibility into MCP tool calls like Tavily Search used by the Researcher Agent.
Installation
pip install crewai 'pylangdb[crewai]' python-dotenv
Project-Structure
report-writing-agent/
├── configs
│ ├── agents.yaml
│ └── tasks.yaml
├── main.py
└── README.mdc
The code snippets below illustrate the key components of the three-agent reporting workflow.
Quick Start Example
The code snippets below illustrate the key components of the three-agent reporting workflow.
Export Environment Variables
export LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
export LANGDB_API_BASE_URL='https://api.langdb.ai'
Initialize Tracing
The first and most important step is to initialize pylangdb tracing before any other CrewAI code runs. This call instruments the environment to automatically capture all agent and tool activity.
from pylangdb.crewai import init
from dotenv import load_dotenv
# Load environment variables and initialize tracing
load_dotenv()
init()
Configure the LLM
First, define a helper function to instantiate LLMs with the necessary LangDB tracing headers. This ensures all model calls are captured.
from crewai import LLM
import os
def create_llm(model):
return LLM(
model=model,
api_key=os.environ.get("LANGDB_API_KEY"),
base_url=os.environ.get("LANGDB_BASE_URL"),
extra_headers={
"x-project-id": os.environ.get("LANGDB_PROJECT_ID")
}
)
Define the Crew
Next, use the @CrewBase decorator to define the agents and tasks, loading configurations from external YAML files.
from crewai import Agent, Task, Crew, Process
from crewai.project import CrewBase, agent, crew, task
@CrewBase
class ReportGenerationCrew():
"""Report Generation crew"""
agents_config = "configs/agents.yaml"
tasks_config = "configs/tasks.yaml"
@agent
def researcher(self) -> Agent:
return Agent(
config=self.agents_config['researcher'],
llm=create_llm("openai/langdb/reportresearcher_9wzgx5n5" ) # LangDB Virtual Model with MCP
)
@agent
def analyst(self) -> Agent:
return Agent(
config=self.agents_config['analyst'],
llm=create_llm("openai/anthropic/claude-3.7-sonnet")
)
# ... report_writer agent definition follows the same pattern ...
@crew
def crew(self) -> Crew:
return Crew(
agents=[self.researcher(), self.analyst(), self.report_writer()],
tasks=[self.research_task(), self.analysis_task(), self.report_writing_task()],
process=Process.sequential
)
Run the Workflow
Finally, instantiate the crew and kickoff() the process with a specific topic.
def generate_report(topic):
crew_instance = ReportGenerationCrew()
# ... update task descriptions with the topic ...
result = crew_instance.crew().kickoff()
return result
if __name__ == "__main__":
generate_report("The Impact of AI on Social Media Marketing in 2024")
Running the script will generate a full trace in LangDB that includes every model call, tool invocation, and inter-agent message.
Configs
agents.yaml
researcher:
role: "Domain Researcher"
goal: "Gather up-to-date information on the given topic"
backstory: "Experienced researcher with expertise in finding credible sources."
tasks.yaml
research_task:
description: >
Research the given topic thoroughly using web search tools.
Gather current information, statistics, trends, and key insights.
Focus on finding credible sources and recent developments.
expected_output: >
A comprehensive research summary with key findings, statistics,
and relevant information about the topic. Include source citations.
Full source code—including additional agents, tasks, and YAML configs—is available in the repository: https://github.com/langdb/langdb-samples/tree/main/examples/crewai/report-writing-agent.
Configuring MCP and Models
To enable the Researcher Agent to retrieve fresh, real‑time information and ensure every search query is recorded for auditing and debugging, we configure a Virtual MCP Server and attach it to a Virtual Model. This setup provides:
- Live Web Search: Integrate external search capabilities directly into your agent.
- Traceability: All MCP tool calls (search queries, parameters, responses) are logged in LangDB for observability and troubleshooting.
- Consistency: Using a dedicated MCP Server ensures uniform search behavior across runs.
Steps To Create a Virtual MCP
- In LangDB UI, navigate to Projects → MCP Servers.
- Click + New Virtual MCP Server:
- Name:
web-search-mcp - Underlying MCP: Tavily Search MCP
- Requires API Key: Make sure Tavily API Key is configured in your environment to authenticate this operation.
- Name:
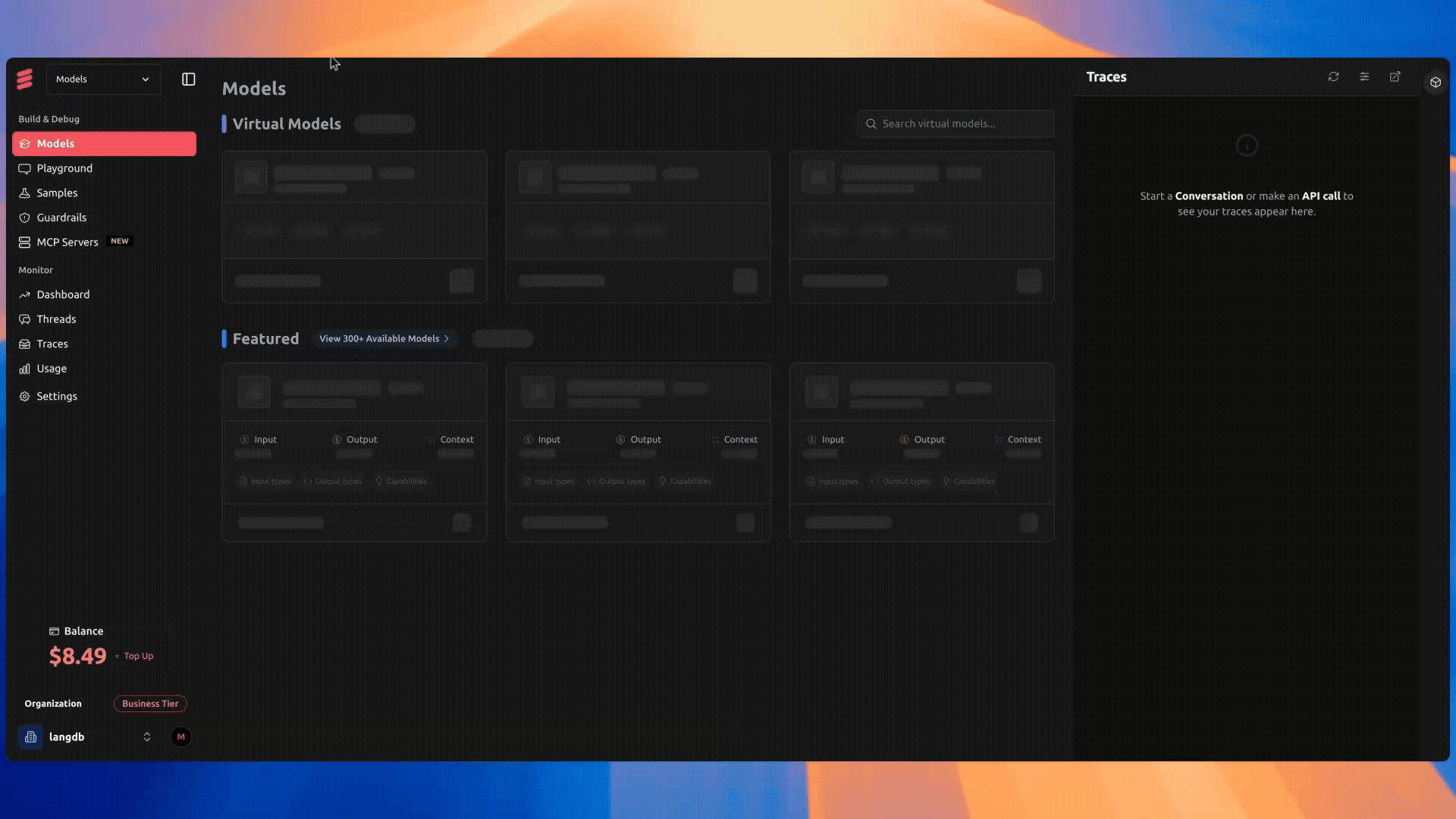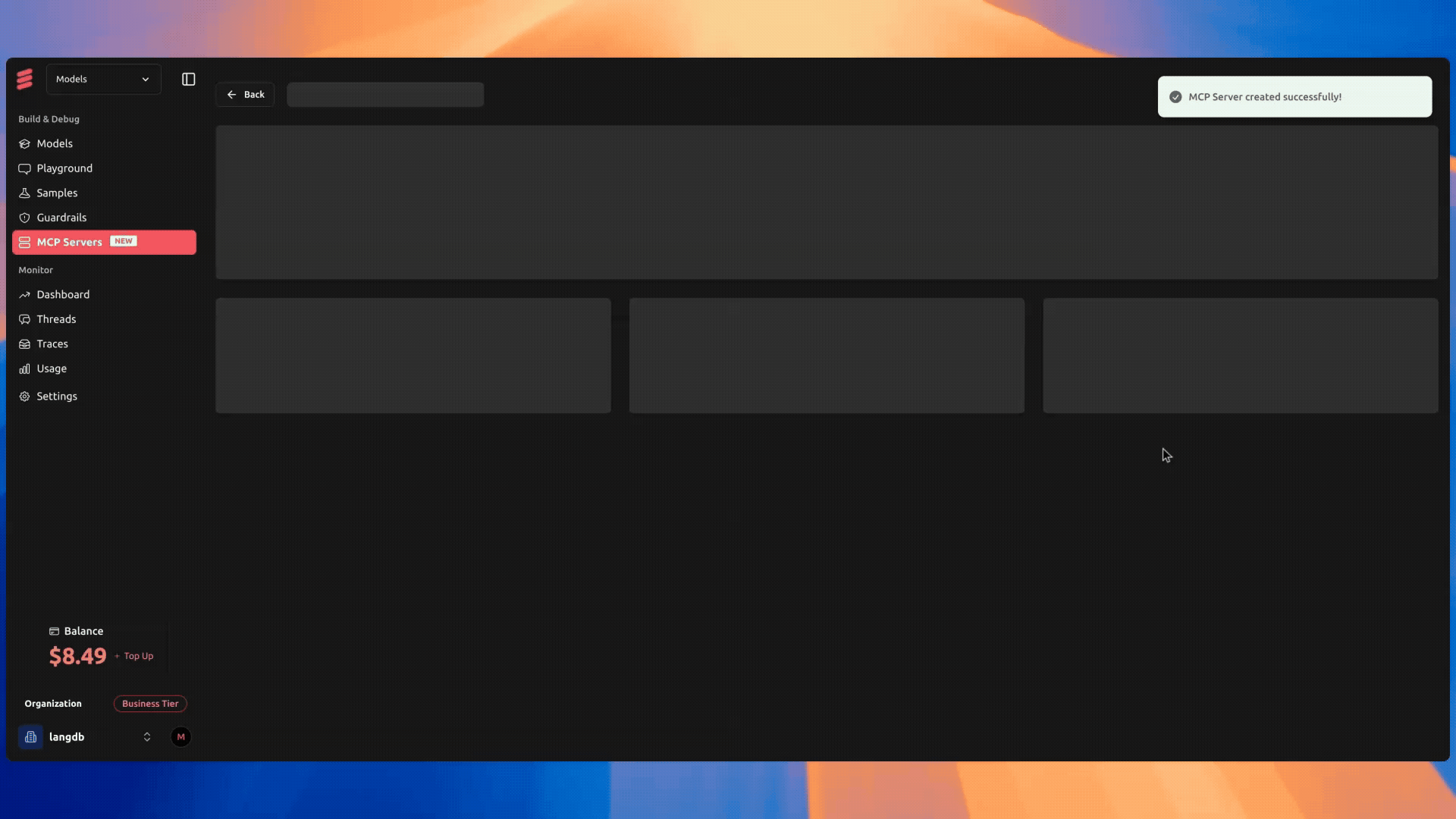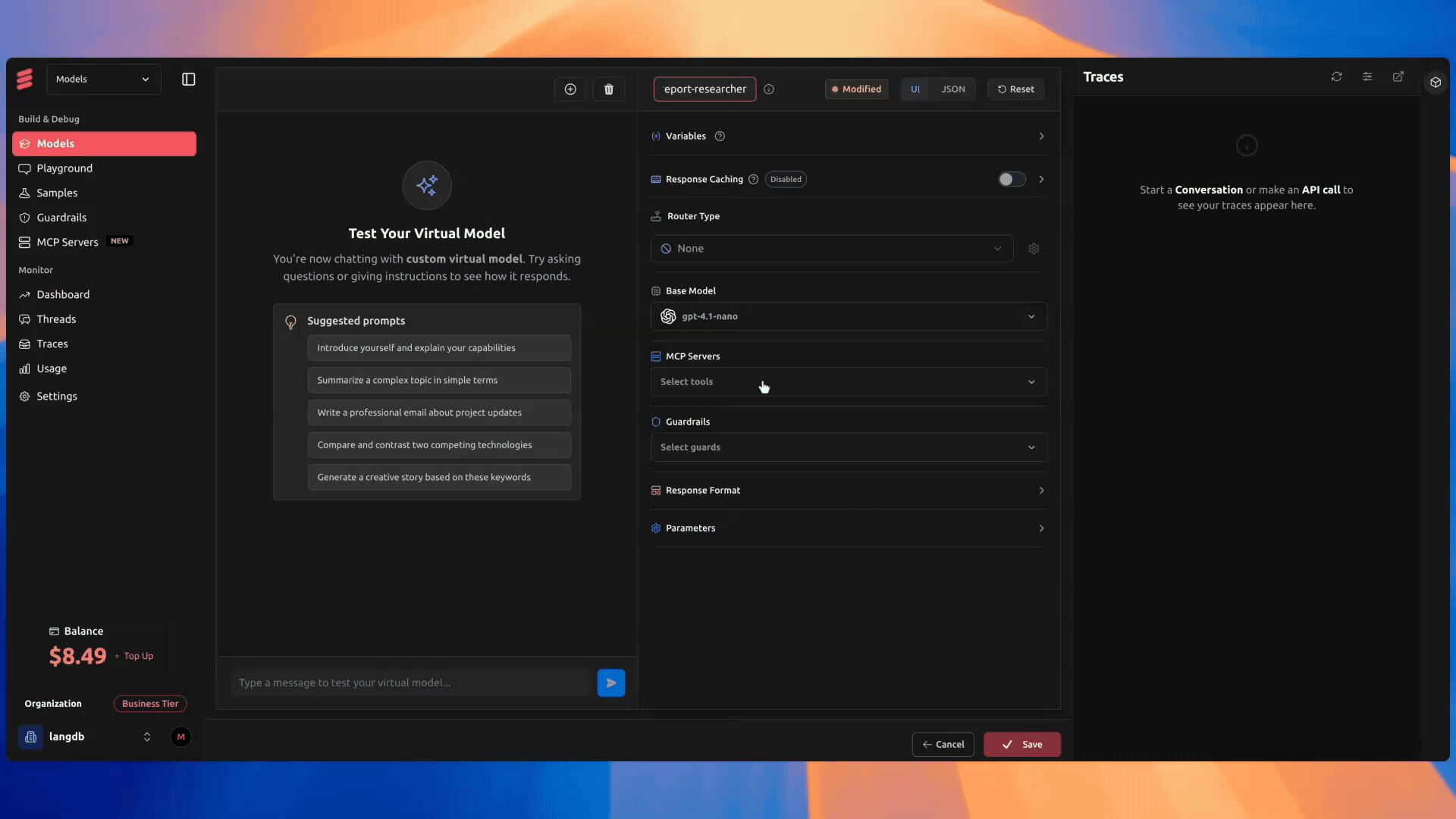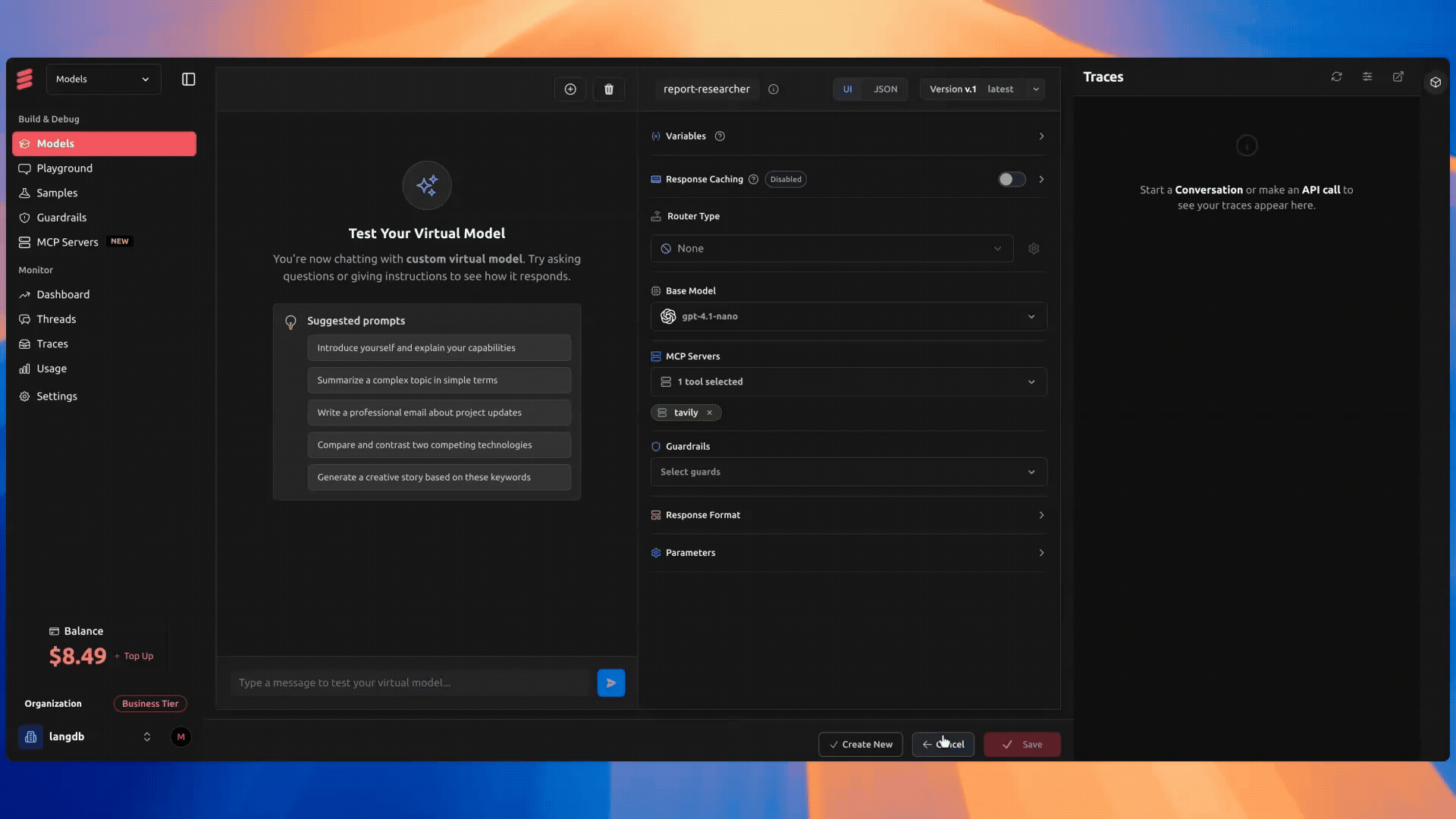
- Navigate to Models → + New Virtual Model:
- Name:
report-researcher - Base Model: GPT-4.1 or similar
- Attach:
web-search-mcpas the search tool
- Name:
- Copy the model identifier (e.g.
openai/langdb/report-researcher) and use it in the Researcher agent.
LangDB will log all MCP calls for traceability.
Custom Model Usage
You can use any model available on LangDB. When specifying a model, ensure it follows the LiteLLM naming convention for provider-specific models (e.g., openai/gpt-4o, anthropic/claude-3-sonnet-20240229). To customize, simply update the create_llm() calls with your preferred model identifiers:
tool_llm = create_llm("openai/langdb/report-researcher")
analysis_llm = create_llm("openai/gpt-4o")
writer_llm = create_llm("openai/google/gemini-2.5-pro")
Ensure the model string matches a valid LangDB or OpenAI namespace. All routing, tracing, and MCP integrations remain identical regardless of the model.
When you create a new Virtual Model in LangDB, it will generate a unique model name (for example,
openai/langdb/report-researcher@v1).
Be sure to replace the example model name in yourmain.pyand in your agent config files with the actual model name generated for your project.
Running the Agent
Execute the workflow by passing a topic:
python main.py "The Impact of AI on Social Media Marketing in 2024"
The CLI will prompt for a topic if none is provided.
Conclusion
Below is a real, shareable example of a generated report and full execution trace using this pipeline:
Checkout: Report Writing Agent Thread using CrewAI