Beating GPT-5
Everyone assumes GPT-5 is untouchable — the safest, most accurate choice for every task. But our latest experiments tell a different story. When we put LangDB's Auto Router head-to-head against GPT-5, the results surprised us.
The Setup
We ran 100 real-world prompts across four categories: Finance, Writing, Science/Math, and Coding. One group always used GPT-5. The other let Auto Router decide the right model.
At first glance, you’d expect GPT-5 to dominate — and in strict A/B judging, it often did. But once we layered in a second check — asking an independent validator whether the Router’s answers were satisfactory (correct, useful, and complete) — the picture flipped.
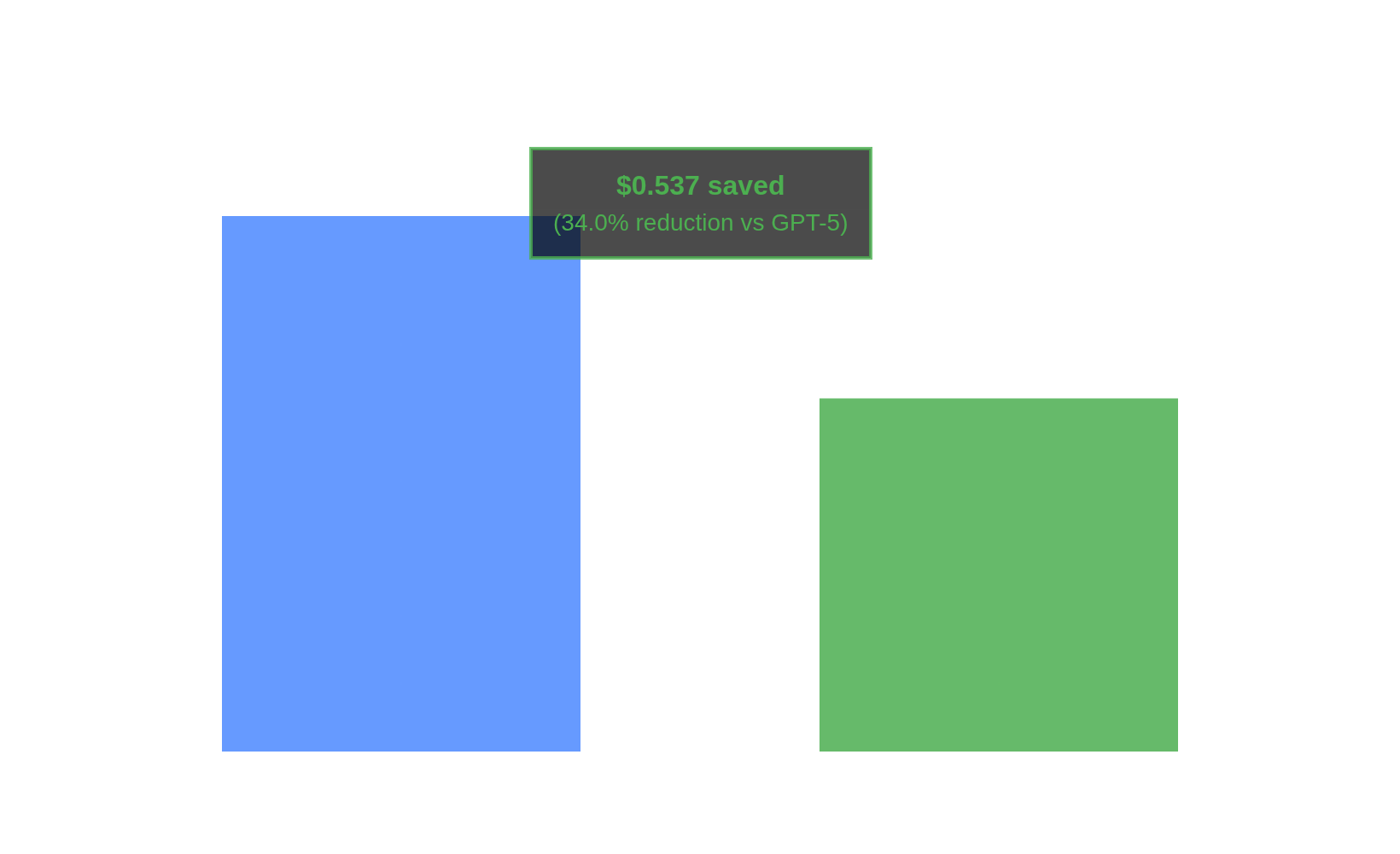
What We Found
- Costs Less: Router cut spend by 35% compared to GPT-5 ($1.04 vs $1.58).
- Good Enough Most of the Time: Router's answers were judged satisfactory in 83% of cases.
- Practical Wins: When you combine Router wins, ties, and “GPT-5 wins but Router still satisfactory,” the Router came out ahead in 86/100 tasks.
- Safe: There were zero catastrophic failures — Router never produced unusable output.
Breaking Down Quality
On strict comparisons, GPT-5 outscored Router in 65 cases. Router directly won 10, with 25 ties. But here’s the catch: in the majority of those “GPT-5 wins,” the Router’s answer was still perfectly fine.
Think about defining a finance term, writing a short code snippet, or solving a straightforward math problem. GPT-5 might give a longer, more polished answer, but Router’s output was clear, correct, and usable — and it cost a fraction of the price.
The validator helped us separate “better” from “good enough.” And for most workloads, good enough at lower cost is exactly what you want.
Where Router Shines (and Struggles)
- Finance: Router was flawless here, delivering satisfactory answers for every single prompt.
- Coding: Router handled structured coding tasks well — effective in 30 out of 32 cases.
- Science/Math: Router held its own, though GPT-5 still had the edge on trickier reasoning.
- Writing: This was the weakest area for Router. GPT-5 consistently produced richer, more polished prose. Still, Router’s outputs were acceptable two-thirds of the time.
Why This Matters
The key takeaway isn’t that Router is “better than GPT-5” in raw accuracy. It’s that Router is better for your budget without compromising real-world quality. By knowing when a smaller model is good enough, you save money while still keeping GPT-5 in reserve for the hardest tasks.
In practice, that means:
- Finance and Coding workloads → Route automatically and trust the savings.
- Open-ended creative writing → Let Router escalate to GPT-5 when needed.
- Everywhere else → Expect huge cost reductions without a hit to user experience.
Try It Yourself
Using the Router doesn’t require any special configuration:
{
"model": "router/auto",
"messages": [
{
"role": "user",
"content": "Define liquidity in finance in one sentence."
}
]
}
Just point to router/auto. LangDB takes care of routing — so you get the right balance of cost and quality, automatically.