Response Caching
Response caching is designed for faster response times, reduced compute cost, and consistent outputs when handling repeated or identical prompts. Perfect for dashboards, agents, and endpoints with predictable queries.
Benefits
- Faster responses for identical requests (cache hit)
- Reduced model/token usage for repeated inputs
- Consistent outputs for the same input and parameters
Using Response Caching
Through Virtual Model
- Toggle Response Caching ON.
- Select the cache type:
- Exact match (default): Matches prompt.
- (Distance-based matching is coming soon.)
- Set Cache expiration time in seconds (default:
1200).
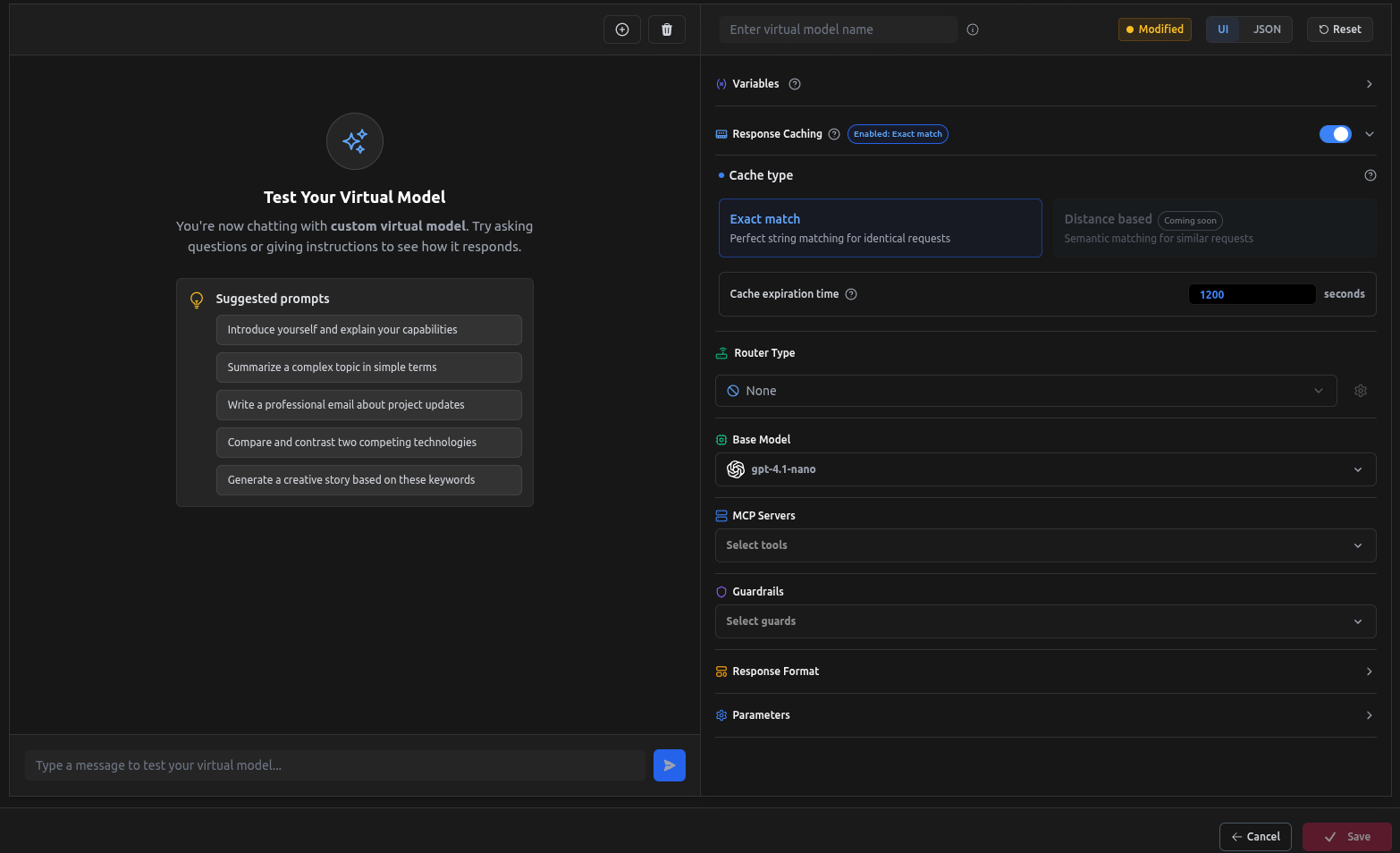
Once enabled, identical requests will reuse the cached output as long as it hasn’t expired.
Through API Calls
You can use caching on a per-request basis by including a cache field in your API body:
{
"model": "openai/gpt-4.1",
"messages": [
{"role": "user", "content": "Summarize the news today"}
],
"cache": {
"type": "exact",
"expiration_time": 1200
}
}
type: Currently onlyexactis supported.expiration_time: Time in seconds (e.g., 1200 for 20 minutes).
If caching is enabled in both the virtual model and the request, the API payload takes priority.
Pricing
- Cache hits are billed at 0.1× the standard token price (90% cheaper than a normal model call).
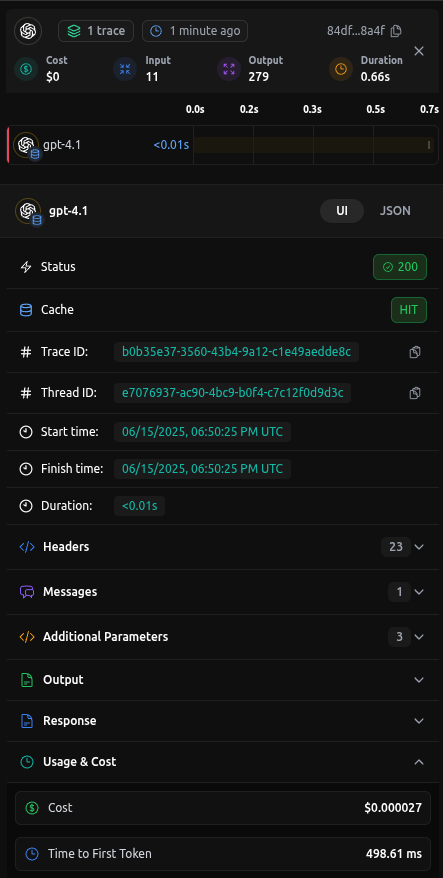
Cache Hits
- When a response is served from cache, it is clearly marked as Cache: HIT in traces.
- You’ll also see:
- Status:
200 - Trace ID and Thread ID for debuging
- Start time / Finish time: Notice how the duration is typically
<0.01sfor cache hits. - Cost: Cache hits are billed at a much lower rate (shown here as
$0.000027).
- Status:
- The “Cache” field is displayed prominently (green “HIT” label).
Response caching in LangDB is a practical way to improve latency, reduce compute costs, and ensure consistent outputs for repeated queries. Use the UI or API to configure caching, monitor cache hits in traces and dashboard, and take advantage of reduced pricing for cached responses.
For most projects with stable or repeated inputs, enabling caching is a straightforward optimization that delivers immediate benefits.