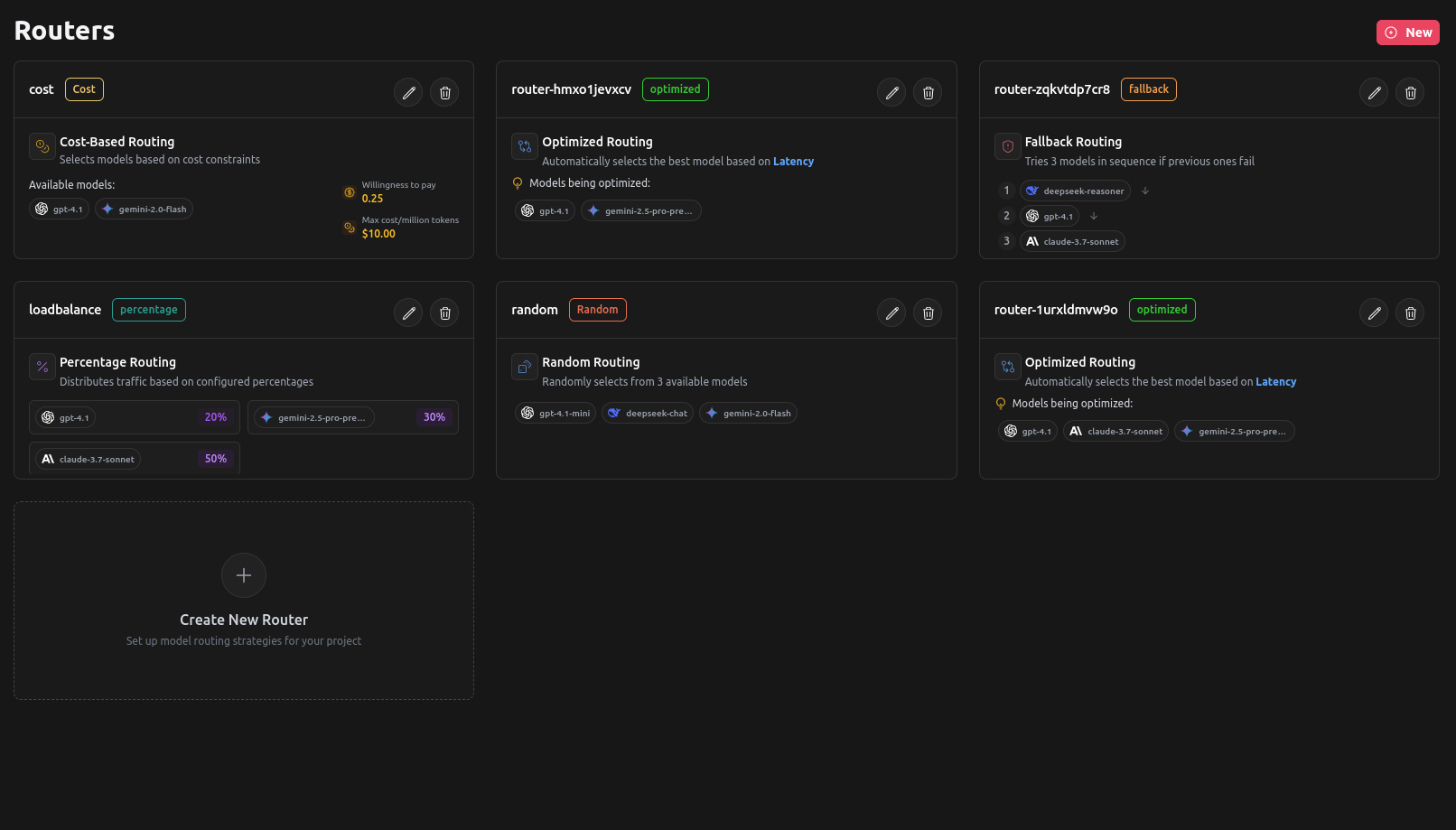
Routing
LangDB AI Gateway optimizes LLM selection based on cost, speed, and availability, ensuring efficient request handling. This guide covers the various dynamic routing strategies available in the system, including fallback, script-based, optimized, percentage-based, and latency-based routing.
This ensures efficient request handling and optimal model selection tailored to specific application needs.
Understanding Targets
Before diving into routing strategies, it's essential to understand targets in LangDB AI Gateway. A target refers to a specific model or endpoint to which requests can be directed. Each target represents a potential processing unit within the routing logic, enabling optimal performance and reliability.
{
"model": "router/dynamic",
"router": {
"type": "percentage",
"targets_percentages": [
40,
60
],
"targets": [
{
"model": "openai/gpt-4.1",
"mcp_servers": [
{
"slug": "mymcp_zoyhbp3u",
"name": "mymcp",
"type": "sse",
"server_url": "https://api.staging.langdb.ai/mymcp_zoyhbp3u"
}
],
"extra": {
"guards": [
"openai_moderation_y6ln88g4"
]
}
},
{
"model": "anthropic/claude-3.7-sonnet",
"mcp_servers": [
{
"slug": "mymcp_zoyhbp3u",
"name": "mymcp",
"type": "sse",
"server_url": "https://api.staging.langdb.ai/mymcp_zoyhbp3u"
}
],
"extra": {
"guards": [
"openai_moderation_y6ln88g4"
]
},
"temperature": 0.6,
"messages": [
{
"content": "You are a helpful assistant",
"id": "02cb4630-b01a-42d9-a226-94968865fbe0",
"role": "system"
}
]
}
]
}
}
Target Parameters
Each target in LangDB is essentially a self-contained configuration, similar to a virtual model. A target can include:
- Model – The identifier for the base model to use (e.g.
openai/gpt-4o) - Prompt – Optional system and user messages to steer the model
- MCP Servers – Support to Virtual MCP Servers
- Guardrails – Validations, Moderations.
- Response Format –
text,json_object, orjson_schema - Custom Parameters – Tuning controls like:
temperaturemax_tokenstop_pfrequency_penaltypresence_penalty
Routing Strategies
LangDB AI Gateway supports multiple routing strategies that can be combined and customized to meet your specific needs:
| Routing Strategy | Description |
|---|---|
| Fallback Routing | Sequentially routes requests through multiple models in case of |
| Optimized Routing | Selects the best model based on real-time performance metrics. |
| Percentage-Based Routing | Distributes traffic between multiple models using predefined weightings. |
| Latency-Based Routing | Chooses the model with the lowest response time for real-time applications. |
| Nested Routing | Combines multiple routing strategies for flexible traffic management. |
Fallback Routing
Fallback routing allows sequential attempts to different model targets in case of failure or unavailability. It ensures robustness by cascading through a list of models based on predefined logic.
{
"model": "router/dynamic",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "What is the formula of a square plot?" }
],
"router": {
"router": "router",
"type": "fallback", // Type: fallback/script/optimized/percentage/latency
"targets": [
{ "model": "openai/gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 },
{ "model": "deepseek/deepseek-chat", "frequency_penalty": 1, "presence_penalty": 0.6 }
]
},
"stream": false
}
Optimized Routing
Optimized routing automatically selects the best model based on real-time performance metrics such as latency, response time, and cost-efficiency.
{
"model": "router/dynamic",
"router": {
"name": "fastest",
"type": "optimized",
"metric": "ttft",
"targets": [
{ "model": "gpt-3.5-turbo", "temperature": 0.8, "max_tokens": 400, "frequency_penalty": 0.5 },
{ "model": "gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 }
]
}
}
Here, the request is routed to the model with the lowest Time-to-First-Token (TTFT) among gpt-3.5-turbo and gpt-4o-mini.
Metrics:
- Requests – Total number of requests sent to the model.
- InputTokens – Number of tokens provided as input to the model.
- OutputTokens – Number of tokens generated by the model in response.
- TotalTokens – Combined count of input and output tokens.
- RequestsDuration – Total duration taken to process requests.
- Ttft (Time-to-First-Token) (Default) – Time taken by the model to generate its first token after receiving a request.
- LlmUsage – The total computational cost of using the model, often used for cost-based routing.
Percentage-Based Routing
Percentage-based routing distributes requests between models according to predefined weightings, allowing load balancing, A/B testing, or controlled experimentation with different configurations. Each model can have distinct parameters while sharing the request load.
{
"model": "router/dynamic",
"router": {
"name": "dynamic",
"type": "percentage",
"targets": [
{ "model": "openai/gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 },
{ "model": "openai/gpt-4o-mini", "temperature": 0.8, "max_tokens": 400, "frequency_penalty": 1 }
],
"targets_percentages": [ 70, 30 ]
}
}
Latency-Based Routing
Latency-based routing selects the model with the lowest response time, ensuring minimal delay for real-time applications like chatbots and interactive AI systems.
{
"model": "router/dynamic",
"router": {
"name": "fastest_latency",
"type": "latency",
"targets": [
{ "model": "openai/gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 },
{ "model": "deepseek/deepseek-chat", "frequency_penalty": 1, "presence_penalty": 0.6 },
{ "model": "gemini/gemini-2.0-flash-exp", "temperature": 0.8, "max_tokens": 400, "frequency_penalty": 0.5 }
]
}
}
Nested Routing
LangDB AI allows nesting of routing strategies, enabling combinations like fallback within script-based selection. This flexibility helps refine model selection based on dynamic business needs.
{
"model": "router/dynamic",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "What is the formula of a square plot?" }
],
"router": {
"type": "fallback",
"targets": [
{
"model": "router/dynamic",
"router": {
"name": "cheapest_script_execution",
"type": "script",
"script": "const route = ({ models }) => models \
.filter(m => m.inference_provider.provider === 'bedrock' && m.type === 'completions') \
.sort((a, b) => a.price.per_input_token - b.price.per_input_token)[0]?.model;"
}
},
{
"model": "router/dynamic",
"router": {
"name": "fastest",
"type": "optimized",
"metric": "ttft",
"targets": [
{ "model": "gpt-3.5-turbo", "temperature": 0.8, "max_tokens": 400, "frequency_penalty": 0.5 },
{ "model": "gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 }
]
}
},
{ "model": "deepseek/deepseek-chat", "temperature": 0.7, "max_tokens": 300, "frequency_penalty": 1 }
]
},
"stream": false
}