Prompt Caching
To save on inference costs, you can leverage prompt caching on supported providers and models. When a provider supports it, LangDB will make a best-effort to route subsequent requests to the same provider to make use of the warm cache.
Most providers automatically enable prompt caching for large prompts, but some, like Anthropic, require you to enable it on a per-message basis.
How Caching Works
Automatic Caching
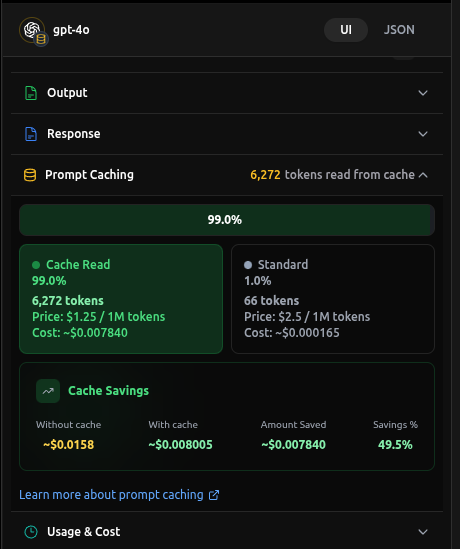
Providers like OpenAI, Grok, DeepSeek, and (soon) Google Gemini enable caching by default once your prompt exceeds a certain length (e.g. 1024 tokens).
- Activation: No change needed. Any prompt over the length threshold is written to cache.
- Best Practice: Put your static content (system prompts, RAG context, long instructions) first in the message so it can be reused.
- Pricing:
- Cache Write: Mostly free or heavily discounted.
- Cache Read: Deep discounts vs. fresh inference.
Manual Caching:
Anthropic’s Claude family requires you to mark which parts of the message are cacheable by adding a cache_control object. You can also set a TTL to control how long the block stays in cache.
- Activation: You must wrap static blocks in a
contentarray and give them acache_controlentry. - TTL: Use
{"ttl": "5m"}or{"ttl": "1h"}to control expiration (default 5 minutes). - Best For: Huge documents, long backstories, or repeated system instructions.
- Pricing:
- Cache Write: 1.25× the normal per-token rate
- Cache Read: 0.1× (10%) of the normal per-token rate
- Limitations: Ephemeral (expires after TTL), limited number of blocks.
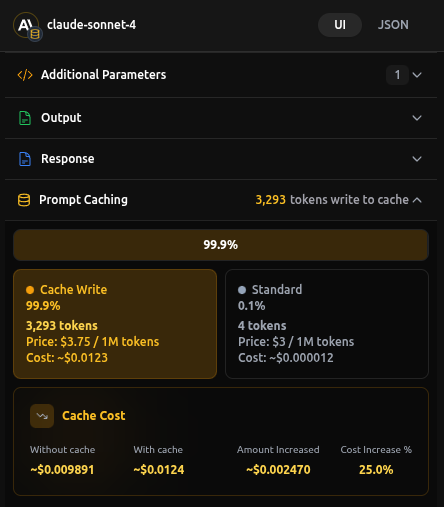
In this run you’ll see “Prompt Caching: 99.9% Write,” a small cost increase (~25%).
Caching Example ( Anthropic)
Here is an example of caching a large document. This can be done in either the system or user message.
{
"model": "anthropic/claude-3.5-sonnet",
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant that analyzes legal documents. The following is a terms of service document:"
},
{
"type": "text",
"text": "HUGE DOCUMENT TEXT...",
"cache_control": {
"type": "ephemeral",
"ttl": "1h"
}
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Summarize the key points about data privacy."
}
]
}
]
}
Provider Support Matrix
| Provider | Auto-cache? | Manual flag? | TTL | Write cost | Read cost |
|---|---|---|---|---|---|
| OpenAI | :white_check_mark: | ❌ | N/A | standard | 0.25x or 0.5x |
| Grok | :white_check_mark: | ❌ | N/A | standard | 0.25x |
| DeepSeek | :white_check_mark: | ❌ | N/A | standard | 0.25x |
| Anthropic Claude | ❌ | cache_control + TTL | 5 m / 1 h | 1.25× | 0.1× |
For the most up-to-date information on a specific model or provider's caching policy, pricing, and limitations, please refer to the model page on LangDB