Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Monitor, Govern and Secure your AI traffic.
An AI gateway is a middleware that acts as a unified access point to multiple LLMs, optimizing, securing, and managing AI traffic. It simplifies integration with different AI providers while enabling cost control, observability, and performance benchmarking. With an AI gateway, businesses can seamlessly switch between models, monitor usage, and optimize costs.
LangDB provides OpenAI compatible APIs to connect with multiple Large Language Models (LLMs) by just changing two lines of code.
Govern, Secure, and Optimize all of your AI Traffic with Cost Control, Optimisation and Full Observability.
What AI Gateway Offers Out of the Box
LangDB provides OpenAI-compatible APIs, enabling developers to connect with multiple LLMs by changing just two lines of code. With LangDB, you can:
Provide access to all major LLMs Ensure seamless integration with leading large language models to maximize flexibility and power.
No framework code required Enable plug-and-play functionality using any framework like Langchain, Vercel AI SDK, CrewAI, etc., for easy adoption.
Plug & Play Tracing & Cost Optimization Simplify implementation of tracing and cost optimization features, ensuring streamlined operations.
Automatic routing based on cost, quality, and other variables Dynamically route requests to the most suitable LLM based on predefined parameters.
Benchmark and provide insights Deliver insights into the best-performing models for specific tasks, such as coding or reasoning, to enhance decision-making.
Quick Start with LangDB
LangDB offers both managed and self hosted versions for organisations to manage AI traffic . Choose between the Hosted Gateway for ease of use or the Open-Source Gateway for full control.
Prompt Caching & Optimization (In Progress) Introduce caching mechanisms to optimize prompt usage and reduce redundant costs.
GuardRails (In Progress) Implement safeguards to enhance reliability and accuracy in AI outputs.
Leaderboard of models per category Create a comparative leaderboard to highlight model performance across categories.
Ready-to-use evaluations for non-data scientists Provide accessible evaluation tools for users without a data science background.
Readily fine-tunable data based on usage Offer pre-configured datasets tailored for fine-tuning, enabling customized improvements with ease.
Quick Start guide for LangDB AI Gateway
The LangDB AI Gateway allows you to connect with multiple Large Language Models (LLMs) instantly, without any setup.





Quick Start
A full featured and managed AI gateway that provides instant access to 250+ LLMs with enterprise ready features.
Self Hosted
A self-hosted option for organizations that require complete control over their AI infrastructure.

Configure temperature, max_tokens, logit_bias, and more with LangDB AI Gateway. Test easily via API, UI, or Playground.
LangDB AI Gateway supports every LLM parameter like temperature, max_tokens, stop sequences, logit_bias, and more.
from openai import OpenAI
response = client.chat.completions.create(
model="gpt-4o", # Change Model
messages=[
{"role": "user", "content": "What are the earnings of Apple in 2022?"},
],
temperature=0.7, # temperature parameter
max_tokens=150, # max_tokens parameter
stream=True # stream parameter
)const response = await client.chat.completions.create({
model: 'gpt-4o-mini',
messages,
temperature: 0.7, // temperature parameter
max_tokens: 150, // max_tokens parameter
logit_bias: { '50256': -100 }, // logit_bias parameter
stream: true, // stream parameter
});You can also use the UI to test various parameters and getting code snippet
Use the Playground to tweak parameters in real time via the Virtual Model config and send test requests instantly.
Explore ready-made code snippets complete with preconfigured parameters—copy, paste, and customize to fit your needs.
Learn how to connect to MCP Servers using LangDB AI Gateway
Instantly connect to managed MCP servers — skip the setup and start using fully managed MCPs with built-in authentication, seamless scalability, and full tracing. This guide gives you a quick walkthrough of how to get started with MCPs.
In this example, we’ll create a Virtual MCP Server by combining Slack and Gmail MCPs — and then connect it to an MCP Client like Cursor for instant access inside your chats.
Select Slack and Gmail from MCP Severs in the Virtual MCP Section.
Generate a Virtual MCP URL automatically.
Install the MCP into Cursor with a single command.
Example install command:
npx @langdb/mcp setup slack_gmail_virtual https://api.langdb.ai/mcp/xxxxx --client cursorAuthentication is handled (via OAuth or API Key)
Full tracing and observability are available (inputs, outputs, errors, latencies)
MCP tools are treated just like normal function calls inside LangDB
MCP Servers listed on LangDB: https://app.langdb.ai/mcp-servers
Explore MCP Usecases.
LangDB provides access to 350+ LLMs with OpenAI compatible APIs.
You can use LangDB as a drop-in replacement for OpenAI APIs, making it easy to integrate into existing workflows and libraries such as OpenAI Client SDK.
You can choose from any of the supported models.
from openai import OpenAI
langdb_project_id = "xxxxx" # LangDB Project ID
client = OpenAI(
base_url=f"https://api.us-east-1.langdb.ai/{langdb_project_id}/v1",
api_key="xxxxx" , # LangDB token
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4", # Change Model
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "What are the earnings of Apple in 2022?"},
],
)
print("Assistant:", response.choices[0].message)import { OpenAI } from 'openai';
const langdbProjectId = 'xxxx'; // LangDB Project ID
const client = new OpenAI({
baseURL: `https://api.us-east-1.langdb.ai/${langdbProjectId}/v1`,
apiKey: 'xxxx' // Your LangDB token,
});
const messages = [
{
role: 'system',
content: 'You are a helpful assistant.'
},
{
role: 'user',
content: 'What are the earnings of Apple in 2022?'
}
];
async function getAssistantReply() {
const { choices } = await client.chat.completions.create({
model: 'gpt-4o-mini',
messages: messages
});
console.log('Assistant:', choices[0].message.content);
}
getAssistantReply();curl "https://api.us-east-1.langdb.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LANGDB_API_KEY" \
-X "X-Project-Id: $Project_ID" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
],
"temperature": 0.8
}'After sending your request, you can see the Traces on the dashboard:
Track complete workflows with LangDB Traces. Get end-to-end visibility, multi-agent support, and error diagnosis.
A Trace represents the complete lifecycle of a workflow, spanning all components and systems involved.
Core Features:
End-to-End Visibility: Tracks model calls, tools across the entire workflow.
Multi Agent Ready: Perfect for workflows that involve multiple services, APIs, or tools.
Error Diagnosis: Quickly identify bottlenecks, failures, or inefficiencies in complex workflows.
Parent-Trace:
For workflows with nested operations (e.g., a workflow that triggers multiple sub-workflows), LangDB introduces the concept of a Parent-Trace, which links the parent workflow to its dependent sub-workflows. This hierarchical structure ensures you can analyze workflows at both macro and micro levels.
Headers for Trace:
trace-id: Tracks the parent workflow.
parent-trace-id: Links sub-workflows to the main workflow for hierarchical tracing.
Manage routing strategies easily in LangDB AI Gateway’s UI to boost efficiency, speed, and reliability in AI workflows.
In LangDB AI Gatewau, any virtual model can act as a router. Just define a strategy and list of target models—it’ll route requests based on metrics like cost, latency, percentage, er or custom rules.
Setting up routing in a virtual model is straightforward:
Open any virtual model in the Chat Playground and click Show Config
Choose a routing strategy (like fallback, optimized, percentage, etc.)
Add your target models—each one can be configured just like the virtual models you set up in the previous section
Each target defines:
Which model to use
Prompt
MCP Servers
Guardrails
Response Format
Custom parameters like temperature, max_tokens, penalties, etc.
All routing options are available directly in the virtual model config panel.
Check more about the .
Learn how to use LangDB to Trace Multi Agent workflows
LangDB automatically visualizes how agents interact, providing a clear view of workflows, hierarchies, and usage patterns by adding and headers.
This allows developers to track interactions between agents seamlessly, ensuring clear visibility into workflows and dependencies.
A multi-agent system consists of independent agents collaborating to solve complex tasks. Agents handle various roles such as user interaction, data processing, and workflow orchestration. LangDB streamlines tracking these interactions for better efficiency and transparency.
Tracking ensures:
Clear Execution Flow: Understand how agents interact.
Performance Optimization: Identify bottlenecks.
Reliability & Accountability: Improve transparency.
LangDB supports two main concepts.
: A complete end-to-end interaction between agents, grouped for easy tracking.
: Aggregate multiple Runs into a single thread for a unified chat experience.
Example
Using the same Run ID and Thread ID across multiple agents ensures seamless tracking, maintaining context across interactions and providing a complete view of the workflow
Checkout the full Multi-Agent Tracing Example .
Track every model call, agent handoff, and tool execution for faster debugging and optimization.
LangDB Gateway provides detailed tracing to monitor, debug, and optimize LLM workflows.
Below is an example of a trace visualization from the dashboard, showcasing a detailed breakdown of the request stages:
In this example trace you’ll find:
Overview Metrics
Cost: Total spend for this request (e.g. $0.034).
Tokens: Input (5,774) vs. output (1,395).
Duration: Total end-to-end latency (29.52 s).
Timeline Breakdown A parallel-track timeline showing each step—from moderation and relevance scoring to model inference and final reply.
Model Invocations**
Every call to gpt-4o-mini, gpt-4o, etc., is plotted with precise start times and durations.
Agent Hand-offs
Transitions between your agents (e.g. search → booking → reply) are highlighted with custom labels like transfer_to_reply_agent.
Tool Integrations
External tools (e.g. booking_tool, travel_tool, python_repl_tool) appear inline with their execution times—so you can spot slow or failed runs immediately.
Guardrails Rules like Min Word Count and Travel Relevance enforce domain-specific constraints and appear in the trace.
With this level of visibility you can quickly pinpoint bottlenecks, understand cost drivers, and ensure your multi-agent pipelines run smoothly.
Explore how LangDB API headers like x-thread-id, x-run-id, x-label, and x-project-id improve LLM tracing, observability, and session tracking for better API management and debugging.
LangDB API provides robust support for HTTP headers, enabling developers to manage API requests efficiently with enhanced tracing, observability, and organization.
These headers play a crucial role in structuring interactions with multiple LLMs by providing tracing, request tracking, and session continuity, making it easier to monitor, and analyze API usage
Usage: Groups multiple related requests under the same conversation
Useful for tracking interactions over a single user session.
Helps maintain context across multiple messages.
Usage: Assigns a custom, human-readable title to a thread.
This title is displayed in the LangDB UI, making it easier to identify and search for specific conversations.
Usage: Makes a thread publicly accessible via a shareable link.
Set the value to 1 or true to enable public sharing.
The public URL will be: https://app.langdb.ai/sharing/threads/{thread_id}
The x-thread-title, if set, will be displayed on the public thread page.
Check for more details.
Usage: Tracks a unique workflow execution in LangDB, such as a model call or tool invocation.
Enables precise tracking and debugging.
Each Run is independent for better observability.
Check for more details.
Usage: Adds a custom tag or label to a LLM Model Call for easier categorization.
Helps with tracing multiple agents.
Check for more details.
Usage: Identifies the project under which the request is being made.
Helps in cost tracking, monitoring, and organizing API calls within a specific project.
Can be set in headers or directly in the API base URL https://api.us-east-1.langdb.ai/${langdbProjectId}/v1
Use LangDB Threads to group messages, maintain conversation context, and enable seamless multi-turn interactions.
A Thread is simply a grouping of Message History that maintains context in a conversation or workflow. Threads are useful for keeping track of past messages and ensuring continuity across multiple exchanges.
Core Features:
Contextual Continuity: Ensures all related Runs are grouped for better observability.
Multi-Turn Support: Simplifies managing interactions that require maintaining state across multiple Runs.
Example:
A user interacting with a chatbot over multiple turns (e.g., asking follow-up questions) generates several messages, but all are grouped under a single Thread to maintain continuity.
Headers for Thread:
x-thread-id: Links all Runs in the same context or conversations.
x-thread-title: Assigns a custom, human-readable title to the thread, making it easier to identify.
x-thread-public: Makes the thread publicly accessible via a shareable link by setting its value to 1 or true.
A Message in LangDB AI Gateway defines structured interactions between users, systems, and models in workflows.
A Message is the basic unit of communication in LangDB workflows. Messages define the interaction between the user, the system, and the model. Every workflow is built around exchanging and processing messages.
Core Features:
Structured Interactions: Messages define roles (user, system, assistant) to organize interactions clearly.
Multi-Role Flexibility: Different roles (e.g., system for instructions, user for queries) enable complex workflows.
Dynamic Responses: Messages form the backbone of LangDB’s chat-based interactions.
Example:
A simple interaction to generate a poem might look like this:
Create Virtual MCP Servers in LangDB AI Gateway to unify tools, manage auth securely, and maintain full observability across workflows
A Virtual MCP Server lets you create a customized set of MCP tools by combining functions from multiple MCP servers — all with scoped access, unified auth, and full observability.
Selective Tools: Pick only the tools you need from existing MCP servers (e.g. Airtable's list_records, GitHub's create_issue, etc.)
Clean Auth Handling: Add your API keys o`nly if needed. Otherwise, LangDB handles OAuth for you.
Full Tracing: Every call is traced on the LangDB — with logs, latencies, input/output, and error metrics.
Easy Integration: Works out of the box with Cursor, Claude, Windsurf, and more.
Version Lock-in: Virtual MCPs are pinned to a specific server version to avoid breaking changes.
Poisoning Safety: Prevents injection or override by malicious tool definitions from source MCPs.
Go to your Virtual MCP server on LangDB Project.
Select the tools you want to include.
(Optional) Add API keys or use LangDB-managed auth.
Click Generate secure MCP URL.
Once you have the MCP URL:
You're now ready to use your selected tools directly inside the editor.
You can also try the Virtual MCP servers by adding the server in the config.
API Endpoints for LangDB
[
{ "role": "system", "content": "You are a helful assistant" },
{ "role": "user", "content": "Write me a poem about celluloids." }
]from openai import OpenAI
from uuid import uuid4
client = OpenAI(
base_url="https://api.us-east-1.langdb.ai/{langdb_project_id}/v1" # LangDB API base URL,
api_key=api_key, # Replace with your LangDB token
)
response1 = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "developer", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}],
extra_headers={"x-thread-id": thread_id, "x-run-id": run_id}
)
# Agent 2 processes the response
response2 = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "developer", "content": "Processing user input."},
{"role": "user", "content": response1.choices[0].message["content"]}],
extra_headers={"x-thread-id": thread_id, "x-run-id": run_id}
)






Track users in LangDB AI Gateway to analyze usage, optimize performance, and improve chatbot experiences.
LangDB AI enables user tracking to collect analytics and monitor usage patterns efficiently. By associating metadata with requests, developers can analyze interactions, optimize performance, and enhance user experience.
For a chatbot service handling multiple users, tracking enables:
Recognizing returning users: Maintain conversation continuity.
Tracking usage trends: Identify common queries to improve responses.
User segmentation: Categorize users using tags (e.g., "websearch", "support").
Analytics: Identify heavy users and allocate resources efficiently.
curl 'https://api.us-east-1.langdb.ai/v1/chat/completions' \
-H 'authorization: Bearer LangDBApiKey' \
-H 'Content-Type: application/json' \
-d '{
"model": "openai/gpt-4o-mini",
"stream": true,
"messages": [
{
"role": "user",
"content": "Def bubbleSort()"
}
],
"extra": {
"user": {
"id": "7",
"name": "mrunmay",
"tags": ["coding", "software"]
}
}
}'extra.user.id: Unique user identifier.
extra.user.name: User alias.
extra.user.tags: Custom tags to classify users (e.g., "coding", "software").
Once users are tracked, analytics and usage APIs can be used to retrieve insights based on id, name, or tags.
Checkout Usage and Analytics section for more details.
Example:
curl -L \
--request POST \
--url 'https://api.us-east-1.langdb.ai/analytics/summary' \
--header 'Authorization: Bearer langDBAPIKey' \
--header 'X-Project-Id: langDBProjectID' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "7",
"user_name": "mrunmay",
"user_tags": ["software", "code"]
}'
Example response:
{
"summary": [
{
"total_cost": 0.00030366,
"total_requests": 1,
"total_duration": 6240.888,
"avg_duration": 6240.9,
"duration": 6240.9,
"duration_p99": 6240.9,
"duration_p95": 6240.9,
"duration_p90": 6240.9,
"duration_p50": 6240.9,
"total_input_tokens": 1139,
"total_output_tokens": 137,
"avg_ttft": 6240.9,
"ttft": 6240.9,
"ttft_p99": 6240.9,
"ttft_p95": 6240.9,
"ttft_p90": 6240.9,
"ttft_p50": 6240.9,
"tps": 204.46,
"tps_p99": 204.46,
"tps_p95": 204.46,
"tps_p90": 204.46,
"tps_p50": 204.46,
"tpot": 0.05,
"tpot_p99": 0.05,
"tpot_p95": 0.05,
"tpot_p90": 0.05,
"tpot_p50": 0.05,
"error_rate": 0.0,
"error_request_count": 0
}
],
"start_time_us": 1737547895565066,
"end_time_us": 1740139895565066
}npx @langdb/mcp setup figma https://api.staging.langdb.ai/mcp/xxxxx --client cursor

Enable end-to-end tracing for AI agent frameworks with LangDB’s one-line init() integration.
LangDB integrates seamlessly with a variety of agent libraries to provide out-of-the-box tracing, observability, and cost insights. By simply initializing the LangDB client adapter for your agent framework, LangDB monkey‑patches the underlying client to inject tracing hooks—no further code changes required.
LangDB Core installed:
pip install 'pylangdb'Optional feature flags (for framework-specific tracing):
pip install 'pylangdb[<library_feature>]'
# e.g. pylangdb[adk], pylangdb[openai_agents]Environment Variables set:
export LANGDB_API_KEY="xxxxx"
export LANGDB_PROJECT_ID="xxxxx"Import and initialize once, before creating or running any agents:
from pylangdb.<library> import init
# Monkey‑patch the client for tracing
init()
# ...then your existing agent setup...Monkey‑patching note: The
init()call wraps key client methods at runtime to capture telemetry. Ensure it runs as early as possible.
GitHub Repo: https://github.com/langdb/pylangdb
pip install 'pylangdb[adk]'from pylangdb.adk import init
init()
from google.adk.agents import Agent
# (rest of your Google ADK agent code)This is an example of complete end-to-end trace using Google ADK and LangDB.
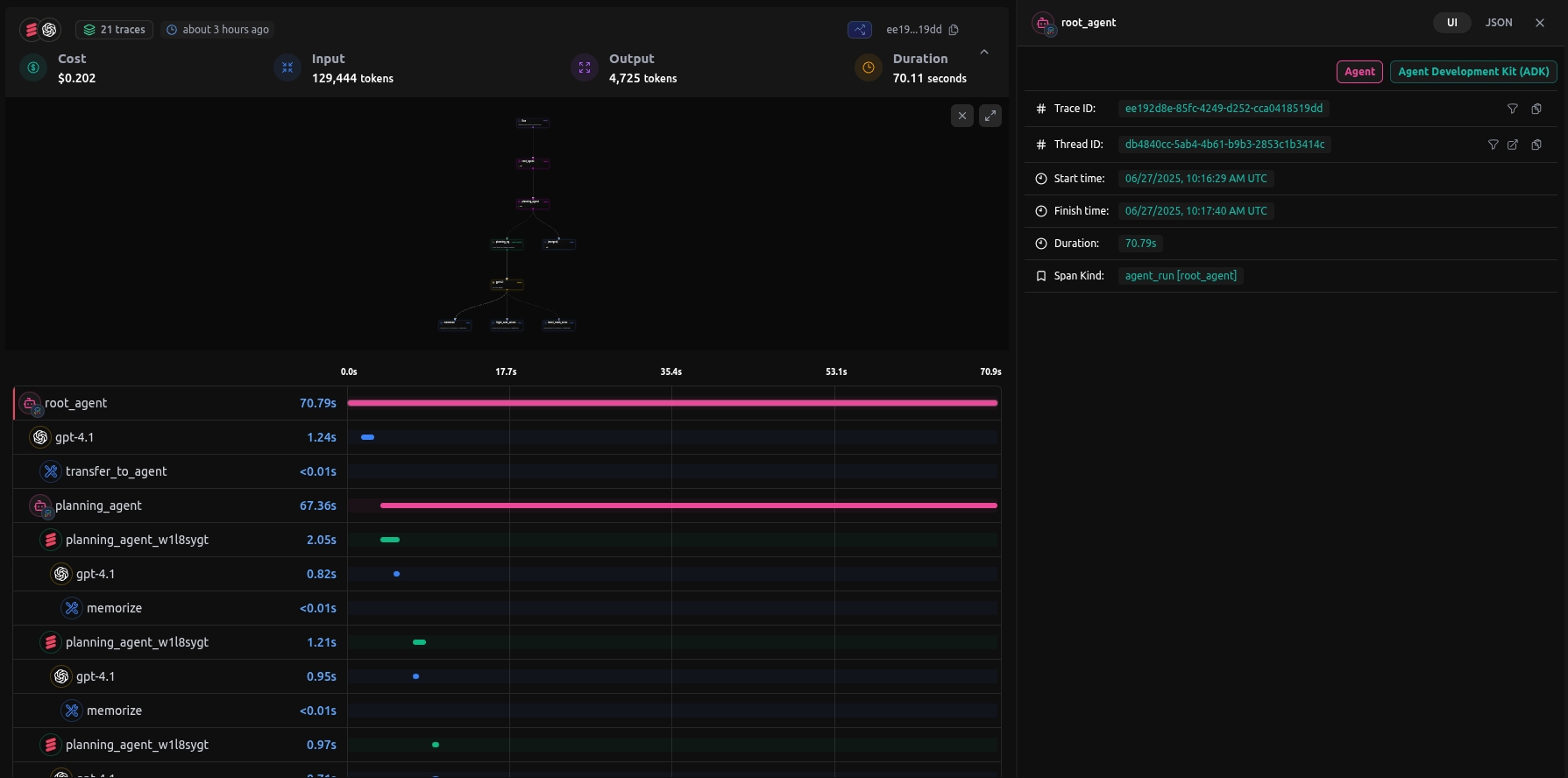
LangDB’s ADK adapter captures request/response metadata, token usage, and latenc metrics automatically. During initialization it discovers and wraps all agents and sub‑agents in subfolders, linking their sessions for full end‑to‑end tracing across your workflow.
For full documentation including client capabilities, configuration, and detailed examples, checkout Python SDK documentation and Github.
Create, manage, and connect MCP servers easily to integrate dynamic tools and enhance your AI workflows with full tracing.
LangDB simplifies how you work with MCP (Model Context Protocol) servers — whether you want to use a built-in Virtual MCP or connect to an external MCP server.
Model Context Protocol (MCP) is an open standard that enables AI models to seamlessly communicate with external systems. It allows models to dynamically process contextual data, ensuring efficient, adaptive, and scalable interactions. MCP simplifies request orchestration across distributed AI systems, enhancing interoperability and context-awareness.
With native tool integrations, MCP connects AI models to APIs, databases, local files, automation tools, and remote services through a standardized protocol. Developers can effortlessly integrate MCP with IDEs, business workflows, and cloud platforms, while retaining the flexibility to switch between LLM providers. This enables the creation of intelligent, multi-modal workflows where AI securely interacts with real-world data and tools.
For more details, visit the Model Context Protocol official page and explore Anthropic MCP documentation.
LangDB allows you to create Virtual MCP Servers directly from the dashboard. You can instantly select and bundle tools like database queries, search APIs, or automation tasks into a single MCP URL — no external setup needed.
Here's an example of how you can use a Virtual MCP Server in your project:
from openai import OpenAI
from uuid import uuid4
client = OpenAI(
base_url="https://api.us-east-1.langdb.ai/LangDBProjectID/v1",
api_key="xxxx",
default_headers={"x-thread-id": str(uuid4())},
)
mcpServerUrl = "Virtual MCP Server URL"
response = client.chat.completions.create(
model="openai/gpt-4.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What are the databases available"}
],
extra_body={
"mcp_servers": [
{
"server_url": mcpServerUrl,
"type": "sse"
}
]
}
)import openai, {
OpenAI
} from 'openai';
import { v4 as uuid4 } from 'uuid';
const client = new OpenAI({
baseURL: "https://api.us-east-1.langdb.ai/LangDBProjectID/v1",
apiKey: "xxxx",
defaultHeaders: {
"x-thread-id": uuid4()
}
});
const mcpServerUrl = 'Virtual MCP URL';
async function getAssistantReply() {
const {
choices
} = await client.chat.completions.create({
model: "openai/gpt-4.1-nano",
messages: [
{role: "system", content: "You are a helpful assistant."},
{role: "user", content: "what are the databases on clickhouse?"} ,
// @ts-expect-error mcp_servers is a LangDB extension
mcp_servers: [
{ server_url: mcpServerUrl, type: 'sse' }
]
}
);
console.log('Assistant:', choices[0].message.content);
}Checkout Virtual MCP and section for usecases.
You can instantly connect LangDB’s Virtual MCP servers to editors like Cursor, Claude, or Windsurf.
Run this in your terminal to set up MCP in Cursor:
npx @langdb/mcp setup <server_name> <mcp_url> --client cursorYou can now call tools directly in your editor, with full tracing on LangDB.
If you already have an MCP server hosted externally — like Smithery’s Exa MCP — you can plug it straight into LangDB with zero extra setup.
Just pass your external MCP server URL in extra_body when you make a chat completion request. For example Smithery:
extra_body = {
"mcp_servers": [
{
"server_url": "wss://your-mcp-server.com/ws?config=your_encoded_config",
"type": "ws"
}
]
}For a complete example of how to use external MCP, refer to the .
Label LLM instances in LangDB AI Gateway for easy tracking, categorization, and improved observability.
Track and monitor complete workflows with Runs in LangDB AI Gateway for better observability, debugging, and insights.
A Run represents a single workflow or operation executed within LangDB. This could be a model invocation, a tool call, or any other discrete task. Each Run is independent and can be tracked separately, making it easier to analyze and debug individual workflows.
Example of a Run:
Core Features:
Granular Tracking: Analyze and optimize the performance and cost of individual Runs.
Independent Execution: Each Run has a distinct lifecycle, enabling precise observability.
Example:
Generating a summary of a document, analyzing a dataset, or fetching information from an external API – each is a Run.
Headers for Run:
x-run-id: Identifies a specific Run for tracking and debugging purposes.
Simplify version control with LangDB Virtual Models’ draft mode—safely iterate, preview, and publish model versions without impacting live traffic.
LangDB’s Virtual Models support a draft mode that streamlines version management and ensures safe, iterative changes. In draft mode, modifications are isolated from the published version until you explicitly publish, giving you confidence that live traffic is unaffected by in-progress edits.
Edit in Draft
Making any change (e.g., adjusting parameters, adding guardrails, modifying messages) flips the version into a Modified draft.
Save Draft
Click Save to record your changes. The draft is saved as a new version at the top of the version list, without affecting the live version.
Live API traffic remains pointed at the last published version.
Publish Draft
Once validated, click Publish:
Saves the version as the new latest version.
Directs all live chat completion traffic to this version.
Keeps the previous published version visible in the list so you can reselect and republish if needed.
Restore & Edit Previous Version
Open the version dropdown and select any listed version.
The selected version loads into the editor.
You can further modify this draft and click Save to create a new version entry.
Re-Publish Any Version
To make any saved version live, select it from the dropdown and click Publish.
All chatCompletions requests to a Virtual Model endpoint automatically target the latest published version. Drafts and restored drafts never receive live traffic until published.
from openai import OpenAI
client = OpenAI(
base_url="https://api.us-east-1.langdb.ai",
api_key=api_key,
)
# Always hits current published version
response = client.chat.completions.create(
model="openai/langdb/my-virtual-model@latest",
messages=[...],
)To preview changes in a draft or restored draft, switch the UI or JSON view selector to that draft and experiment in the Virtual Model Editor — all without impacting production calls.
Iterate Safely: Leverage drafts for experimental guardrails or parameter tuning without risking production stability.
Frequent Publishing: Keep version history granular—publish stable drafts regularly to simplify tracking and rollbacks.
Use Restore Thoughtfully: Before restoring, ensure any important unsaved draft work is committed or intentionally discarded.
Control project expenses by setting user and group-based limits, monitoring AI usage, and optimizing costs in LangDB.
LangDB enables cost tracking, project budgeting, and cost groups to help manage AI usage efficiently.
Available in Business & Enterprise tiers under User Management.
Organize users into cost groups to track and allocate spending.
Cost groups help in budgeting but are independent of user roles.
Set daily, monthly, and total spending limits per project.
Enforce per-user limits to prevent excessive usage.
Available in Project Settings → Cost Control.
Admins and Billing users can define spending limits for cost groups.
Set daily, monthly, and total budgets per group.
Useful for controlling team-based expenses independently of project limits.
Set user permissions with LangDB’s role-based system, giving Admins, Developers, and Billing users specific access and controls.
LangDB provides role-based access control to manage users efficiently within an organization. There are three primary roles: Admin, Developer, and Billing.
Each role has specific permissions and responsibilities, ensuring a structured and secure environment for managing teams.
Admins have the highest level of control within LangDB. They can:
Invite and manage users
Assign and modify roles for team members
Manage cost groups and usage tracking
Access billing details and payment settings
Configure organizational settings
Configure project model access restrictions
Configure project user access restrictions
Best for: Organization owners, team leads, or IT administrators managing team access and billing.
Developers focus on working with APIs and integrating LLMs. They have the following permissions:
Access and use LangDB APIs
Deploy and test applications using LangDB’s AI Gateway
View and monitor API usage and performance
Best for: Software developers, data scientists, and AI engineers working on LLM integrations.
Billing users have access to financial and cost-related features. Their permissions include:
Managing top-ups and subscriptions
Monitoring usage costs and optimizing expenses
Best for: Finance teams, accounting personnel, and cost management administrators.
Admins can assign roles to users when inviting them to the organization. Role changes can also be made later through the user management panel.
Users can have multiple roles (e.g., both Developer and Billing).-
Only Admins can assign or update roles.
Billing users cannot modify API access but can track and manage costs.
Role Management is only available in Professional, Business, and Enterprise tiers.
Learn how to connect your own custom MCP servers to LangDB AI Gateway.
While LangDB provides a rich library of pre-built MCP servers, you can also bring your own. By connecting a custom MCP server, you can leverage all the benefits of a Virtual MCP Server, including:
Unified Interface: Combine your custom tools with tools from other LangDB-managed servers.
Clean Auth Handling: Let LangDB manage authentication, or provide your own API keys and headers.
Full Observability: Get complete tracing for every call, with logs, latencies, and metrics.
Seamless Integration: Works out-of-the-box with clients like Cursor, Claude, and Windsurf.
Enhanced Security: Benefit from version pinning and protection against tool definition poisoning.
This guide explains how to connect your own custom MCP server, whether it uses an HTTP (REST API) or SSE (Server-Sent Events) transport.
When creating a Virtual MCP Server, you can add your own server alongside the servers deployed and managed by LangDB.
Navigate to MCP Servers: Go to the "MCP Servers" section in your LangDB project and click "Create Virtual MCP Server".
Add a Custom Server: In the "Server Configuration" section, click the "+ Add Server" button on the right and select "Custom" from the list.
Configure Server Details: A new "Custom Server" block will appear on the left. Fill in the following details:
Server Name: Give your custom server a descriptive name.
Transport Type: Choose either HTTP (REST API) or SSE (Server-Sent Events) from the dropdown.
HTTP/SSE URL: Enter the endpoint URL for your custom MCP server. LangDB will attempt to connect to this URL to validate the server and fetch the available tools.
(Optional) HTTP Headers: If your server requires specific HTTP headers for authentication or other purposes, you can add them here.
(Optional) Environment Variables: If your server requires specific configuration via environment variables, you can add them.
Select Tools: Once LangDB successfully connects to your server, it will display a list of all the tools exposed by your MCP server. You can select which tools you want to include in your Virtual MCP Server.
Generate URL: After configuring your custom server and selecting the tools, you can generate the secure URL for your Virtual MCP Server and start using it in your applications.
Control which users have access to your projects with LangDB's project-level user access restrictions.
Select which users in your organization can access specific projects. Only Admins can configure project access - other roles cannot modify these settings.
Admin-only configuration: Only Admins can enable/disable user access per project
User-level control: Individual users can be granted or revoked project access
Role preservation: Users keep their organization roles but may be restricted from certain projects
API enforcement: Users without project access cannot make API calls to restricted projects
Project Settings → Users → User Access Configuration
Search and select users to grant project access
Toggle individual users on/off for the project
Use "All Users" toggle to quickly enable/disable everyone
Save configuration
Enabled: User can access the project and make API calls
Disabled: User cannot access the project (blocked from API calls)
All Users toggle: Bulk enable/disable all organization users for the project
Sensitive projects: Restrict access to confidential or regulated projects
Client work: Limit project access to specific team members working with particular clients
Development stages: Control access to production vs development projects
Cost management: Prevent unauthorized usage by limiting project access
Check if the user is enabled for the specific project
Verify the user exists in the organization
Confirm the project access configuration is saved
Only Admin role can configure project access
Ensure you're in the correct project settings
LangDB's Auto Router delivers 83% satisfactory results at 35% lower cost than GPT-5. Real-world testing across 100 prompts shows router optimization without quality compromise.
Everyone assumes GPT-5 is untouchable — the safest, most accurate choice for every task. But our latest experiments tell a different story. When we put LangDB's Auto Router head-to-head against GPT-5, the results surprised us.
We ran 100 real-world prompts across four categories: Finance, Writing, Science/Math, and Coding. One group always used GPT-5. The other let Auto Router decide the right model.
At first glance, you’d expect GPT-5 to dominate — and in strict A/B judging, it often did. But once we layered in a second check — asking an independent validator whether the Router’s answers were satisfactory (correct, useful, and complete) — the picture flipped.
Costs Less: Router cut spend by 35% compared to GPT-5 ($1.04 vs $1.58).
Good Enough Most of the Time: Router's answers were judged satisfactory in 83% of cases.
Practical Wins: When you combine Router wins, ties, and “GPT-5 wins but Router still satisfactory,” the Router came out ahead in 86/100 tasks.
Safe: There were zero catastrophic failures — Router never produced unusable output.
On strict comparisons, GPT-5 outscored Router in 65 cases. Router directly won 10, with 25 ties. But here’s the catch: in the majority of those “GPT-5 wins,” the Router’s answer was still perfectly fine.
Think about defining a finance term, writing a short code snippet, or solving a straightforward math problem. GPT-5 might give a longer, more polished answer, but Router’s output was clear, correct, and usable — and it cost a fraction of the price.
The validator helped us separate “better” from “good enough.” And for most workloads, good enough at lower cost is exactly what you want.
Finance: Router was flawless here, delivering satisfactory answers for every single prompt.
Coding: Router handled structured coding tasks well — effective in 30 out of 32 cases.
Science/Math: Router held its own, though GPT-5 still had the edge on trickier reasoning.
Writing: This was the weakest area for Router. GPT-5 consistently produced richer, more polished prose. Still, Router’s outputs were acceptable two-thirds of the time.
The key takeaway isn’t that Router is “better than GPT-5” in raw accuracy. It’s that Router is better for your budget without compromising real-world quality. By knowing when a smaller model is good enough, you save money while still keeping GPT-5 in reserve for the hardest tasks.
In practice, that means:
Finance and Coding workloads → Route automatically and trust the savings.
Open-ended creative writing → Let Router escalate to GPT-5 when needed.
Everywhere else → Expect huge cost reductions without a hit to user experience.
Using the Router doesn’t require any special configuration:
{
"model": "router/auto",
"messages": [
{
"role": "user",
"content": "Define liquidity in finance in one sentence."
}
]
}Just point to router/auto. LangDB takes care of routing — so you get the right balance of cost and quality, automatically.
Enable response caching in LangDB for faster, lower-cost results on repeated LLM queries.
Response caching is designed for faster response times, reduced compute cost, and consistent outputs when handling repeated or identical prompts. Perfect for dashboards, agents, and endpoints with predictable queries.
Faster responses for identical requests (cache hit)
Reduced model/token usage for repeated inputs
Consistent outputs for the same input and parameters
Toggle Response Caching ON.
Select the cache type:
Exact match (default): Matches prompt.
(Distance-based matching is coming soon.)
Set Cache expiration time in seconds (default: 1200).
Once enabled, identical requests will reuse the cached output as long as it hasn’t expired.
You can use caching on a per-request basis by including a cache field in your API body:
type: Currently only exact is supported.
expiration_time: Time in seconds (e.g., 1200 for 20 minutes).
If caching is enabled in both the virtual model and the request, the API payload takes priority.
Cache hits are billed at 0.1× the standard token price (90% cheaper than a normal model call).
When a response is served from cache, it is clearly marked as Cache: HIT in traces.
You’ll also see:
Status: 200
Trace ID and Thread ID for debuging
Start time / Finish time: Notice how the duration is typically <0.01s for cache hits.
Cost: Cache hits are billed at a much lower rate (shown here as $0.000027).
The “Cache” field is displayed prominently (green “HIT” label).
Response caching in LangDB is a practical way to improve latency, reduce compute costs, and ensure consistent outputs for repeated queries. Use the UI or API to configure caching, monitor cache hits in traces and dashboard, and take advantage of reduced pricing for cached responses.
For most projects with stable or repeated inputs, enabling caching is a straightforward optimization that delivers immediate benefits.
Control which models are available in your projects with LangDB's model access restrictions, ensuring teams only use approved models.
Restrict which AI models are available for specific projects. Only Admins can configure these restrictions - other roles are bound by the settings.
Admin-only configuration: Only Admins can set which models are allowed per project
API enforcement: Restricted models return access denied errors
Team-wide: All project members are bound by the same restrictions
Universal: Works across all API endpoints and integrations
Project Settings → Model
Select allowed models from the list
Save configuration
Test with an API call to verify restrictions are working.
Cost control: Restrict expensive models in dev environments
Production stability: Only allow tested models in production
Compliance: Meet regulatory requirements by limiting model access
"Model not available" errors:
Check if the model is in the project's allowed list
Verify model restrictions are enabled
Confirm you're using the correct model identifier
Can't modify restrictions:
Only Admin role can configure restrictions
{
"model": "openai/gpt-4.1",
"messages": [
{"role": "user", "content": "Summarize the news today"}
],
"cache": {
"type": "exact",
"expiration_time": 1200
}
}


Google ADK
OpenAI Agents SDK
LangGraph
Agno
CrewAI














Unlock full observability for CrewAI agents and tasks—capture LLM calls, task execution, and agent interactions with LangDB’s init().
LangDB’s Agno integration provides end-to-end tracing for your Agno agent pipelines.
Install the LangDB client with Agno feature flag:
Set your LangDB credentials:
Import and run the initialize before configuring your Agno Code:
All Agno interactions from invocation through tool calls to final output are traced with LangDB.
Here is a full example based on Web Search Agno Multi Agent Team.
Check out the full sample on GitHub:
Navigate to the parent directory of your agent project and use one of the following commands:
When you run queries against your agent, LangDB automatically captures detailed traces of all agent interactions:
This guide covered the basics of integrating LangDB with Agno using a Web Search agent example. For more complex scenarios and advanced use cases, check out our comprehensive resources in .
Instrument Google ADK pipelines with LangDB—capture nested agent flows, token usage, and latency metrics using a single init() call.
LangDB’s Google ADK integration provides end-to-end tracing for your ADK agent pipelines.
Enable end-to-end tracing for your Google ADK agents by installing the pylangdb client with the ADK feature flag:
Set your environment variables before initializing running the script:
Initialize LangDB before creating or running any ADK agents:
Once initialized, LangDB automatically discovers all agents and sub-agents (including nested folders), wraps their key methods at runtime, and links sessions for full end-to-end tracing across your workflow as well.
Here's a full example of a Google ADK agent implementation that you can instrument with LangDB. This sample is based on the official .
Check out the full sample on GitHub:
Create the following project structure:
Create an __init__.py file in the multi_tool_agent folder:
Create .env file for your secrets
Create an agent.py file with the following code:
Navigate to the parent directory of your agent project and use the following commands:
Open the URL provided (usually http://localhost:8000) in your browser and select "multi_tool_agent" from the dropdown menu.
Once your agent is running, try these example queries to test its functionality:
These queries will trigger the agent to use the functions we defined and provide responses based on the our agent workflow.
When you run queries against your ADK agent, LangDB automatically captures detailed traces of all agent interactions:
This guide covered the basics of integrating LangDB with Google ADK using a simple weather and time agent example. For more complex scenarios and advanced use cases, check out our comprehensive resources in .
Automatically route requests across multiple AI providers for optimal cost, latency, and accuracy. One model name, multiple providers.
Stop worrying about which provider to pick. With Provider Routing, you can call a model by name, and LangDB will automatically select the right provider for you.
One Name, Many Providers – Call a model like deepseek-v3.1 and LangDB picks from DeepSeek official, Parasail, DeepInfra, Fireworks AI, and more.
Optimize by Mode – Choose whether you want lowest cost, fastest latency, highest accuracy, or simply balanced routing.
That’s it — LangDB will resolve deepseek-v3.1 across multiple providers, and by default use balanced mode.
When you specify only a model name, LangDB chooses the provider according to your selected mode.
LangDB chooses the provider dynamically, balancing cost, latency, and accuracy.
LangDB picks the cheapest provider for deepseek-v3.1 based on input/output token prices (e.g. Parasail, Fireworks AI, or DeepInfra if they’re lower than DeepSeek official).
Routes to the provider with the highest benchmark score for deepseek-v3.1.
Always picks the provider with the fastest response times.
Distributes requests across all available providers for deepseek-v3.1 to maximize scale.
If you want full control, you can always specify the provider explicitly:
This bypasses provider routing and always uses the given provider.
Use model without provider → LangDB does provider routing.
Add :mode suffix → pick between balanced, accuracy, cost, latency, or throughput.
Use provider/model → pin a specific provider directly.
Provider Routing makes it easy to scale across multiple vendors without rewriting your code.
Track total usage, model-specific metrics, and user-level analytics to stay within limits and optimize LLM workflows.
Monitoring complements tracing by providing aggregate insights into the usage of LLM workflows.
LangDB enforces limits to ensure fair usage and cost management while allowing users to configure these limits as needed. Limits are categorized into:
Daily Limits: Maximum usage per day, e.g., $10 in the Starter Tier.
Monthly Limits: Total usage allowed in a month, e.g., $100.
Total Limits: Cumulative limit over the project’s duration, e.g., $500.
Monitor usage regularly to avoid overages.
Plan limits based on project needs and anticipated workloads.
Upgrade tiers if usage consistently approaches limits.
Setting limits not only helps you stay within budget but also provides the flexibility to scale your usage as needed, ensuring your projects run smoothly and efficiently.
Retrieves the total usage statistics for your project for a timeframe.
Example Response:
Fetches timeseries usage statistics per model, allowing users to analyze the distribution of LLM usage.
Example Response:
As discussed in User Tracking, we can use filters to retrieve insights based on id, name, or tags.
Available Filters:
user_id: Filter data for a specific user by their unique ID.
user_name: Retrieve usage based on the user’s name.
user_tags: Filter by tags associated with a user (e.g., "websearch", "support").
Example response:
{
"model": "deepseek-v3.1",
"messages": [
{
"role": "user",
"content": "Explain reinforcement learning in simple terms."
}
]
}balanced
Distributes requests across providers for optimal overall performance
General apps (default)
accuracy
Routes to the provider with the best benchmark score
Research, compliance
cost
Picks the cheapest provider by input/output token price
Support chatbots, FAQs
latency
Always selects the lowest latency provider
Real-time UIs, voice bots
throughput
Spreads requests across all providers to maximize concurrency
High-volume pipelines
{
"model": "deepseek-v3.1",
"messages": [{ "role": "user", "content": "Summarize this article." }]
}{
"model": "deepseek-v3.1:cost",
"messages": [{ "role": "user", "content": "Write a short FAQ response." }]
}{
"model": "deepseek-v3.1:accuracy",
"messages": [{ "role": "user", "content": "Solve this math word problem." }]
}{
"model": "deepseek-v3.1:latency",
"messages": [{ "role": "user", "content": "Respond quickly for a live chat." }]
}{
"model": "deepseek-v3.1:throughput",
"messages": [{ "role": "user", "content": "Translate this dataset." }]
}{
"model": "parasail/deepseek-v3.1",
"messages": [{ "role": "user", "content": "Generate a poem." }]
}curl --location 'https://api.us-east-1.langdb.ai/usage/total' \
--header 'x-project-id: langdbProjectID' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer langDBAPIKey' \
--data '{"start_time_us": 1693062345678,
"end_time_us": 1695092345678}'{
"total": {
"total_input_tokens": 4181386,
"total_output_tokens": 206547,
"total_cost": 11.890438685999994
},
"period_start": 1737504000000000,
"period_end": 1740131013885000
}curl --location 'https://api.us-east-1.langdb.ai/usage/models' \
--header 'x-project-id: langdbProjectID' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer langDBAPIKey' \
--data '{"start_time_us": 1693062345678, "end_time_us": 1695092345678,
"min_unit": "hour"} '{
"models": [
{
"hour": "2025-02-14 08:00:00",
"provider": "openai",
"model_name": "gpt-4o-mini",
"total_input_tokens": 13408,
"total_output_tokens": 2169,
"total_cost": 0.0039751199999999995
},
{
"hour": "2025-02-13 08:00:00",
"provider": "openai",
"model_name": "gpt-4o-mini",
"total_input_tokens": 55612,
"total_output_tokens": 786,
"total_cost": 0.01057608
}
],
"period_start": 1737504000000000,
"period_end": 1740130915098000
}curl -L \
--request POST \
--url 'https://api.us-east-1.langdb.ai/usage/models' \
--header 'Authorization: Bearer langDBAPIKey' \
--header 'X-Project-Id: langDBProjectID' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "123",
"user_name": "mrunmay",
"user_tags": ["websearch", "testings"]
}'{
"models": [
{
"day": "2025-02-21 10:00:00",
"provider": "openai",
"model_name": "gpt-4o-mini",
"total_input_tokens": 1112,
"total_output_tokens": 130,
"total_cost": 0.00029376
},
{
"day": "2025-02-21 14:00:00",
"provider": "openai",
"model_name": "gpt-4o-mini",
"total_input_tokens": 3317,
"total_output_tokens": 328,
"total_cost": 0.00083322
}
],
"period_start": 1737556513673410,
"period_end": 1740148513673410
}


pip install 'pylangdb[agno]'export LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"from pylangdb.agno import init
# Initialise LangDB
init()import os
from pylangdb.agno import init
init()
from agno.agent import Agent
from agno.tools.duckduckgo import DuckDuckGoTools
from agno.models.langdb import LangDB
# Configure LangDB-backed model
langdb_model = LangDB(
id="openai/gpt-4",
api_key=os.getenv("LANGDB_API_KEY"),
project_id=os.getenv("LANGDB_PROJECT_ID"),
)
# Create and run your agent
agent = Agent(
name="Web Agent",
role="Search the web for information",
model=langdb_model,
tools=[DuckDuckGoTools()],
instructions="Answer questions using web search",
)
response = agent.run("What is LangDB?")
print(response)pip install agno 'pylangdb[agno]' duckduckgo-searchexport LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"import os
from textwrap import dedent
# Initialize LangDB tracing and import model
from pylangdb.agno import init
init()
from agno.models.langdb import LangDB
# Import Agno agent components
from agno.agent import Agent
from agno.tools.duckduckgo import DuckDuckGoTools
# Function to create a LangDB model with selectable model name
def create_langdb_model(model_name="openai/gpt-4.1"):
return LangDB(
id=model_name,
api_key=os.getenv("LANGDB_API_KEY"),
project_id=os.getenv("LANGDB_PROJECT_ID"),
)
web_agent = Agent(
name="Web Agent",
role="Search the web for comprehensive information and current data",
model=create_langdb_model("openai/gpt-4.1"),
tools=[DuckDuckGoTools()],
instructions="Always use web search tools to find current and accurate information. Search for multiple aspects of the topic to gather comprehensive data.",
show_tool_calls=True,
markdown=True,
)
writer_agent = Agent(
name="Writer Agent",
role="Write comprehensive article on the provided topic",
model=create_langdb_model("anthropic/claude-3.7-sonnet"),
instructions="Use outlines to write articles",
show_tool_calls=True,
markdown=True,
)
agent_team = Agent(
name="Research Team",
team=[web_agent, writer_agent],
model=create_langdb_model("gemini/gemini-2.0-flash"),
instructions=dedent("""\
You are the coordinator of a research team with two specialists:
1. Web Agent: Has DuckDuckGo search tools and must be used for ALL research tasks
2. Writer Agent: Specializes in creating comprehensive articles
WORKFLOW:
1. ALWAYS delegate research tasks to the Web Agent first
2. The Web Agent MUST use web search tools to gather current information
3. Then delegate writing tasks to the Writer Agent using the research findings
4. Ensure comprehensive coverage of the topic through multiple searches
IMPORTANT: Never attempt to answer without first having the Web Agent conduct searches.
"""),
show_tool_calls=True,
markdown=True,
)
agent_team.print_response(
"I need a comprehensive article about the Eiffel Tower. "
"Please have the Web Agent search for current information about its history, architectural significance, and cultural impact. "
"Then have the Writer Agent create a detailed article based on the research findings.",
stream=True
)python main.py
pip install 'pylangdb[adk]'export LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"from pylangdb.adk import init
# Initialise LangDB
init()
# Then proceed with your normal ADK setup:
from google.adk.agents import Agent
# ...define and run agents...pip install google-adk litellm 'pylangdb[adk]'parent_folder/
└── multi_tool_agent/
├── __init__.py
├── agent.py
└── .envfrom . import agentLANGDB_API_KEY="<your_langdb_api_key>"
LANGDB_PROJECT_ID="<your_langdb_project_id>"# First initialize LangDB before defining any agents
from pylangdb.adk import init
init()
import datetime
from zoneinfo import ZoneInfo
from google.adk.agents import Agent
def get_weather(city: str) -> dict:
if city.lower() != "new york":
return {"status": "error", "error_message": f"Weather information for '{city}' is not available."}
return {"status": "success", "report": "The weather in New York is sunny with a temperature of 25 degrees Celsius (77 degrees Fahrenheit)."}
def get_current_time(city: str) -> dict:
if city.lower() != "new york":
return {"status": "error", "error_message": f"Sorry, I don't have timezone information for {city}."}
tz = ZoneInfo("America/New_York")
now = datetime.datetime.now(tz)
return {"status": "success", "report": f'The current time in {city} is {now.strftime("%Y-%m-%d %H:%M:%S %Z%z")}'}
root_agent = Agent(
name="weather_time_agent",
model="gemini-2.0-flash",
description=("Agent to answer questions about the time and weather in a city." ),
instruction=("You are a helpful agent who can answer user questions about the time and weather in a city."),
tools=[get_weather, get_current_time],
)adk webWhats the weather in New York?
Leverage provider-side prompt caching for significant cost and latency savings on large, repeated prompts.
To save on inference costs, you can leverage prompt caching on supported providers and models. When a provider supports it, LangDB will make a best-effort to route subsequent requests to the same provider to make use of the warm cache.
Most providers automatically enable prompt caching for large prompts, but some, like Anthropic, require you to enable it on a per-message basis.
Providers like OpenAI, Grok, DeepSeek, and (soon) Google Gemini enable caching by default once your prompt exceeds a certain length (e.g. 1024 tokens).
Activation: No change needed. Any prompt over the length threshold is written to cache.
Best Practice: Put your static content (system prompts, RAG context, long instructions) first in the message so it can be reused.
Pricing:
Cache Write: Mostly free or heavily discounted.
Cache Read: Deep discounts vs. fresh inference.
Anthropic’s Claude family requires you to mark which parts of the message are cacheable by adding a cache_control object. You can also set a TTL to control how long the block stays in cache.
Activation: You must wrap static blocks in a content array and give them a cache_control entry.
TTL: Use {"ttl": "5m"} or {"ttl": "1h"} to control expiration (default 5 minutes).
Best For: Huge documents, long backstories, or repeated system instructions.
Pricing:
Cache Write: 1.25× the normal per-token rate
Cache Read: 0.1× (10%) of the normal per-token rate
Limitations: Ephemeral (expires after TTL), limited number of blocks.
Here is an example of caching a large document. This can be done in either the system or user message.
{
"model": "anthropic/claude-3.5-sonnet",
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant that analyzes legal documents. The following is a terms of service document:"
},
{
"type": "text",
"text": "HUGE DOCUMENT TEXT...",
"cache_control": {
"type": "ephemeral",
"ttl": "1h"
}
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Summarize the key points about data privacy."
}
]
}
]
}OpenAI
✅
❌
N/A
standard
0.25x or 0.5x
Grok
✅
❌
N/A
standard
0.25x
DeepSeek
✅
❌
N/A
standard
0.25x
Anthropic Claude
❌
cache_control + TTL
5 m / 1 h
1.25×
0.1×
For the most up-to-date information on a specific model or provider's caching policy, pricing, and limitations, please refer to the model page on LangDB
Save costs without losing quality. Auto Router delivers best-model accuracy at a fraction of the price.
Most developers assume that using the best model is the safest bet for every query. But in practice, that often means paying more than you need to — especially when cheaper models can handle simpler queries just as well.
LangDB’s Auto Router shows you don’t always need the “best” model — just the right model for the job.
When building AI applications, you face a constant trade-off: performance vs. cost. Do you always use the most powerful (and expensive) model to guarantee quality? Or do you risk cheaper alternatives that might fall short on complex tasks?
We wanted to find out: Can smart routing beat the "always use the best model" strategy?
We designed a head-to-head comparison using 100 real-world queries across four domains: Finance, Writing, Science/Math, and Coding. Each query was tested against two strategies:
Auto Router → Analyzed query complexity and topic, then selected the most cost-effective model that could handle the task
Router:Accuracy → Always defaulted to the highest-performing model (the "best model" approach)
What made this test realistic:
Diverse complexity: 70 low-complexity queries (simple conversions, definitions) and 30 high-complexity queries (complex analysis, multi-step reasoning)
Real-world domains: Finance calculations, professional writing, scientific explanations, and coding problems
Impartial judging: Used GPT-5-mini as an objective judge to compare response quality
Sample of what we tested:
Finance: "A company has revenue of $200M and expenses of $150M. What is its profit?"
Writing: "Write a one-line professional email subject requesting a meeting"
Science/Math: "Convert 100 cm into meters"
Coding: "Explain what a variable is in programming in one sentence"
Win → Auto Router chose a cheaper model, and the output was equal or better than the best model.
Tie → Auto Router escalated to the best model itself, because the query was complex enough to require it.
Loss → Didn’t happen. Auto Router never underperformed compared to always using the best model.
In other words: Auto Router matched or beat the best model strategy 100% of the time — while cutting costs by ~42%.
In Finance and Writing, Auto Router confidently used cheaper models most of the time.
In Coding, Auto Router often escalated to the best model — proving it knows when not to compromise.
How Auto Router Works: Auto Router doesn't just pick models randomly. It uses a sophisticated classification system that:
Analyzes query complexity — Is this a simple fact lookup or a complex reasoning task?
Identifies the domain — Finance, writing, coding, or science/math?
Matches to optimal model — Selects the most cost-effective model that can handle the specific complexity level
The "Always Best" Approach: Router:Accuracy takes the conservative route — always selecting the highest-performing model regardless of query complexity. It's like using a Formula 1 car for grocery shopping.
Fair Comparison: We used GPT-5-mini as an impartial judge to evaluate response quality across both strategies. The judge compared answers based on correctness, usefulness, and completeness without knowing which routing strategy was used.
The Real-World Impact:
Cost optimization without compromise — Save 42% on API costs while maintaining quality
Intelligent escalation — Complex queries automatically get the best models
No manual tuning — The router handles the complexity analysis for you
Using Auto Router is simple — just point to router/auto:
Auto Router will automatically select the most cost-effective model that can handle your query complexity.
Save Money → Auto Router avoids overpaying on simple queries
Stay Accurate → For complex cases, it automatically picks the strongest model
Smarter Than "Always Best" → Matches or beats the best-model-only approach at a fraction of the cost
You don't need to pick the "best" model every time.
With Auto Router:
Simple queries → cheaper models save you money
Complex queries → stronger models keep accuracy intact
Overall → 100% accuracy parity at 42% lower cost
That's the power of LangDB Auto Router.
Total Cost
$0.95
$1.64
Wins
65%
0%
Ties
35%
35%
Losses
0%
0%
Accuracy Parity
100% (wins + ties)
100%
Finance
25
23
2
Writing
24
18
6
Science & Math
19
14
5
Coding
32
10
22
{
"model": "router/auto",
"messages": [
{
"role": "user",
"content": "A company has revenue of $200M and expenses of $150M. What is its profit?"
}
]
}


Add end-to-end tracing to Agno agent workflows with LangDB—monitor model calls, tool usage, and step flows using a single init() call.
LangDB makes it effortless to trace CrewAI workflows end-to-end. With a single init() call, all agent interactions, task executions, and LLM calls are captured.
Install the LangDB client with LangChain feature flag:
pip install 'pylangdb[crewai]'Set your LangDB credentials:
export LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"Import and run the initialize before configuring your CrewAI Code:
from pylangdb.crewai import init
# Initialise LangDB
init()import os
from dotenv import load_dotenv
from crewai import Agent, Task, Crew, LLM
# Configure LLM with LangDB headers
llm = LLM(
model="openai/gpt-4o", # Use LiteLLM Like Model Names
api_key=os.getenv("LANGDB_API_KEY"),
base_url=os.getenv("LANGDB_API_BASE_URL"),
extra_headers={"x-project-id": os.getenv("LANGDB_PROJECT_ID")}
)
# Define agents and tasks as usual
researcher = Agent(
role="researcher",
goal="Research topic thoroughly",
backstory="You are an expert researcher",
llm=llm,
verbose=True
)
task = Task(description="Research the given topic", agent=researcher)
crew = Crew(agents=[researcher], tasks=[task])
# Kick off the workflow
result = crew.kickoff()
print(result)All CrewAI calls—agent initialization, task execution, and model responses—are automatically linked.
Here is a full example based on CrewAI report writing agent.
Check out the full sample on GitHub: https://github.com/langdb/langdb-samples/tree/main/examples/crewai/crewai-tracing
pip install crewai 'pylangdb[crewai]' crewai_tools setuptools python-dotenvYou also need to get API Key from Serper.dev
export LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'#!/usr/bin/env python3
import os
import sys
from pylangdb.crewai import init
init()
from dotenv import load_dotenv
from crewai import Agent, Task, Crew, Process, LLM
from crewai_tools import SerperDevTool
load_dotenv()
def create_llm(model):
return LLM(
model=model,
api_key=os.environ.get("LANGDB_API_KEY"),
base_url=os.environ.get("LANGDB_API_BASE_URL"),
extra_headers={"x-project-id": os.environ.get("LANGDB_PROJECT_ID")}
)
class ResearchPlanningCrew:
def researcher(self) -> Agent:
return Agent(
role="Research Specialist",
goal="Research topics thoroughly",
backstory="Expert researcher with skills in finding information",
tools=[SerperDevTool()],
llm=create_llm("openai/gpt-4o"),
verbose=True
)
def planner(self) -> Agent:
return Agent(
role="Strategic Planner",
goal="Create actionable plans based on research",
backstory="Strategic planner who breaks down complex challenges",
reasoning=True,
max_reasoning_attempts=3,
llm=create_llm("openai/anthropic/claude-3.7-sonnet"),
verbose=True
)
def research_task(self) -> Task:
return Task(
description="Research the topic thoroughly and compile information",
agent=self.researcher(),
expected_output="Comprehensive research report"
)
def planning_task(self) -> Task:
return Task(
description="Create a strategic plan based on research",
agent=self.planner(),
expected_output="Strategic execution plan with phases and goals",
context=[self.research_task()]
)
def crew(self) -> Crew:
return Crew(
agents=[self.researcher(), self.planner()],
tasks=[self.research_task(), self.planning_task()],
verbose=True,
process=Process.sequential
)
def main():
topic = sys.argv[1] if len(sys.argv) > 1 else "Artificial Intelligence in Healthcare"
crew_instance = ResearchPlanningCrew()
# Update task descriptions with topic
crew_instance.research_task().description = f"Research {topic} thoroughly and compile information"
crew_instance.planning_task().description = f"Create a strategic plan for {topic} based on research"
result = crew_instance.crew().kickoff()
print(result)
if __name__ == "__main__":
main()Navigate to the parent directory of your agent project and use one of the following commands:
python main.pyWhen you run queries against your agent, LangDB automatically captures detailed traces of all agent interactions:
This guide covered the basics of integrating LangDB with CrewAI using a Research and Planning agent example. For more complex scenarios and advanced use cases, check out our comprehensive resources in .
LangDB project ID
10100A list of threads with pagination info
POST /threads HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 25
{
"limit": 10,
"offset": 100
}A list of threads with pagination info
{
"data": [
{
"id": "123e4567-e89b-12d3-a456-426614174000",
"created_at": "2025-10-01T19:41:01.782Z",
"updated_at": "2025-10-01T19:41:01.782Z",
"model_name": "text",
"project_id": "text",
"score": 1,
"title": "text",
"user_id": "text"
}
],
"pagination": {
"limit": 10,
"offset": 100,
"total": 10
}
}Create, save, and reuse LLM configurations with Virtual Models in LangDB AI Gateway to streamline workflows and ensure consistent behavior.
LangDB’s Virtual Models let you save, share, and reuse model configurations—combining prompts, parameters, tools, and routing logic into a single named unit. This simplifies workflows and ensures consistent behavior across your apps, agents, and API calls.
Once saved, these configurations can be quickly accessed and reused across multiple applications.
Virtual models in LangDB are more than just model aliases. They are fully configurable AI agents that:
Let you define system/user messages upfront
Support routing logic to dynamically choose between models
Include MCP integrations and guardrails
Are callable from UI playground, API, and LangChain/OpenAI SDKs
Use virtual models to manage:
Prompt versioning and reuse
Consistent testing across different models
Precision tuning with per-model parameters
Seamless integration of tools and control logic
Routing using strategies like fallback, percentage-based, latency-based, optimized, and script-based selection
Go to the Models
Click on Create Virtual Model.
Set prompt messages — define system and user messages to guide model behavior
Set variables (optional) — useful if your prompts require dynamic values
Select router type
None: Use a single model only
Fallback, Random, Cost,Percentage, Latency, Optimized: Configure smart routing across targets. Checkout all .
Add one or more targets
Each target defines a model, mcp servers, guardrails, system-user messages, response format and its parameters (e.g. temperature, max_tokens, top_p, penalties)
Select MCP Servers — connect tools like LangDB Search, Code Execution, or others
Add guardrails (optional) — for validation, transformation, or filtering logic
Set response format — choose between text, json_object, or json_schema
Give your virtual model a name and Save.
Your virtual model now appears in the Models section of your project, ready to be used anywhere a model is accepted.
You can edit virtual models anytime. LangDB supports formal versioning via the @version syntax:
langdb/my-model@latest or langdb/my-model → resolves to the latest version
langdb/my-model@v1 or langdb/my-model@1 → resolves to version 1
This allows you to safely test new versions, roll back to older ones, or maintain multiple stable variants of a model in parallel.
Once saved, your virtual model is fully available across all LangDB interfaces:
Chat Playground: Select it from the model dropdown and test interactively.
OpenAI-Compatible SDKs: Works seamlessly with OpenAI clients by changing only the model name.
LangChain / CrewAI / other frameworks: Call it just like any base model by using model="langdb/my-model@latest" or a specific version like @v1.
This makes virtual models a portable, modular building block across all parts of your AI stack.



Trace OpenAI Agents SDK workflows end-to-end with LangDB—monitor model calls, tool invocations, and runner sessions via one-line init().
LangDB helps you add full tracing and observability to your OpenAI Agents SDK workflows—without changing your core logic. With a one-line initialization, LangDB captures model calls, tool invocations, and intermediate steps, giving you a complete view of how your agent operates.
Enable end-to-end tracing for your OpenAI Agents SDK agents by installing the pylangdb client with the openai feature flag:
pip install 'pylangdb[openai]'Set your LangDB credentials:
export LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"Import and run the initialize before configuring your OpenAI client:
from pylangdb.openai import init
# Initialise LangDB
init()# Agent SDK imports
from agents import (
Agent,
Runner,
set_default_openai_client,
RunConfig,
ModelProvider,
Model,
OpenAIChatCompletionsModel
)
from openai import AsyncOpenAI
# Configure the OpenAI client with LangDB headers
client = AsyncOpenAI(
api_key=os.environ["LANGDB_API_KEY"],
base_url=os.environ["LANGDB_API_BASE_URL"],
default_headers={"x-project-id": os.environ["LANGDB_PROJECT_ID"]}
)
set_default_openai_client(client)
# Create a custom model provider for advanced routing
class CustomModelProvider(ModelProvider):
def get_model(self, model_name: str | None) -> Model:
return OpenAIChatCompletionsModel(model=model_name, openai_client=client)
agent = Agent(
name="Math Tutor",
instructions="You are a helpful assistant",
model="openai/gpt-4.1", # Choose any model from avaialable model on LangDB
)
# Register your custom model provider to route model calls through LangDB
CUSTOM_MODEL_PROVIDER = CustomModelProvider()
# Assign a unique group_id to link all steps in this session trace
group_id = str(uuid.uuid4())
response = await Runner.run(
agent,
input="Hello, world!",
run_config=RunConfig(
model_provider=CUSTOM_MODEL_PROVIDER, # Inject custom model provider
group_id=group_id # Link all steps to the same trace
)
)Once executed, LangDB links all steps—model calls, intermediate tool usage, and runner orchestration—into a single session trace.
Here is a full example based on OpenAI Agents SDK Quickstart which uses LangDB Tracing.
Check out the full sample on GitHub: https://github.com/langdb/langdb-samples/tree/main/examples/openai/openai-agents-tracing
pip install openai-agents 'pylangdb[openai]'export LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"# Initialize LangDB tracing
from pylangdb.openai import init
init()
# Agent SDK imports
from agents import (
Agent,
Runner,
set_default_openai_client,
set_default_openai_key,
set_default_openai_api,
RunConfig,
ModelProvider,
Model,
OpenAIChatCompletionsModel
)
from openai import AsyncOpenAI
import os
import uuid
import asyncio
# Configure the OpenAI client with LangDB headers
client = AsyncOpenAI(api_key=os.environ["LANGDB_API_KEY"],
base_url=os.environ["LANGDB_API_BASE_URL"],
default_headers={"x-project-id": os.environ["LANGDB_PROJECT_ID"]})
# Set the configured client as default with tracing enabled
set_default_openai_client(client, use_for_tracing=True)
set_default_openai_api(api="chat_completions")
# set_default_openai_key(os.environ["LANGDB_API_KEY"])
# Create a custom model provider for advanced routing
class CustomModelProvider(ModelProvider):
def get_model(self, model_name: str | None) -> Model:
return OpenAIChatCompletionsModel(model=model_name, openai_client=client)
# Register your custom model provider to route model calls through LangDB
CUSTOM_MODEL_PROVIDER = CustomModelProvider()
math_tutor_agent = Agent(
name="Math Tutor",
handoff_description="Specialist agent for math questions",
instructions="You provide help with math problems. Explain your reasoning at each step and include examples",
model="anthropic/claude-3.7-sonnet"
)
history_tutor_agent = Agent(
name="History Tutor",
handoff_description="Specialist agent for historical questions",
instructions="You provide assistance with historical queries. Explain important events and context clearly.",
model="gemini/gemini-2.0-flash" # Choose any model available on LangDB
)
triage_agent = Agent(
name="Triage Agent",
instructions="You determine which agent to use based on the user's homework question",
handoffs=[history_tutor_agent, math_tutor_agent],
model="openai/gpt-4o-mini" # Choose any model available on LangDB
)
# Assign a unique group_id to link all steps in this session trace
group_id = str(uuid.uuid4())
# Define async function to run the agent
async def run_agent():
response = await Runner.run(
triage_agent,
input="who was the first president of the united states?",
run_config=RunConfig(
model_provider=CUSTOM_MODEL_PROVIDER, # Inject custom model provider
group_id=group_id # Link all steps to the same trace
)
)
print(response.final_output)
# Run the async function with asyncio
asyncio.run(run_agent())
Navigate to the parent directory of your agent project and use one of the following commands:
python main.pyThe first president of the United States was **George Washington**.
Here's some important context:
* **The American Revolution (1775-1783):** Washington was the commander-in-chief of the Continental Army during the Revolutionary War. His leadership was crucial in securing American independence from Great Britain.
* **The Articles of Confederation (1781-1789):** After the war, the United States was governed by the Articles of Confederation. This system proved to be weak and ineffective, leading to calls for a stronger national government.
* **The Constitutional Convention (1787):** Delegates from the states met in Philadelphia to revise the Articles of Confederation. Instead, they drafted a new Constitution that created a more powerful federal government. Washington presided over the convention, lending his prestige and influence to the process.
* **The Constitution and the Presidency:** The Constitution established the office of the President of the United States.
* **Election of 1789:** George Washington was unanimously elected as the first president by the Electoral College in 1789. There were no opposing candidates. This reflected the immense respect and trust the nation had in him.
* **First Term (1789-1793):** Washington established many precedents for the presidency, including the formation of a cabinet, the practice of delivering an annual address to Congress, and the idea of serving only two terms. He focused on establishing a stable national government, paying off the national debt, and maintaining neutrality in foreign affairs.
* **Second Term (1793-1797):** Washington faced challenges such as the Whiskey Rebellion and growing partisan divisions. He decided to retire after two terms, setting another crucial precedent for peaceful transitions of power.
* **Significance:** Washington's leadership and integrity were essential in establishing the legitimacy and credibility of the new government. He is often considered the "Father of His Country" for his pivotal role in the founding of the United States.When you run queries against your agent, LangDB automatically captures detailed traces of all agent interactions:
This guide covered the basics of integrating LangDB with OpenAI Agents SDK using a history and maths agent example. For more complex scenarios and advanced use cases, check out our comprehensive resources in .
Intelligently route across multiple LLMs to ensure fast, reliable, and scalable AI operations.
LangDB AI Gateway optimizes LLM selection based on cost, speed, and availability, ensuring efficient request handling. This guide covers the various dynamic routing strategies available in the system, including fallback, script-based, optimized, percentage-based, and latency-based routing.
This ensures efficient request handling and optimal model selection tailored to specific application needs.
Before diving into routing strategies, it's essential to understand targets in LangDB AI Gateway. A target refers to a specific model or endpoint to which requests can be directed. Each target represents a potential processing unit within the routing logic, enabling optimal performance and reliability.
{
"model": "router/dynamic",
"router": {
"type": "percentage",
"targets_percentages": [
40,
60
],
"targets": [
{
"model": "openai/gpt-4.1",
"mcp_servers": [
{
"slug": "mymcp_zoyhbp3u",
"name": "mymcp",
"type": "sse",
"server_url": "https://api.staging.langdb.ai/mymcp_zoyhbp3u"
}
],
"extra": {
"guards": [
"openai_moderation_y6ln88g4"
]
}
},
{
"model": "anthropic/claude-3.7-sonnet",
"mcp_servers": [
{
"slug": "mymcp_zoyhbp3u",
"name": "mymcp",
"type": "sse",
"server_url": "https://api.staging.langdb.ai/mymcp_zoyhbp3u"
}
],
"extra": {
"guards": [
"openai_moderation_y6ln88g4"
]
},
"temperature": 0.6,
"messages": [
{
"content": "You are a helpful assistant",
"id": "02cb4630-b01a-42d9-a226-94968865fbe0",
"role": "system"
}
]
}
]
}
}Target Parameters
Each target in LangDB is essentially a self-contained configuration, similar to a virtual model. A target can include:
Model – The identifier for the base model to use (e.g. openai/gpt-4o)
Prompt – Optional system and user messages to steer the model
MCP Servers – Support to Virtual MCP Servers
Guardrails – Validations, Moderations.
Response Format – text, json_object, or json_schema
Custom Parameters – Tuning controls like:
temperature
max_tokens
top_p
frequency_penalty
presence_penalty
LangDB AI Gateway supports multiple routing strategies that can be combined and customized to meet your specific needs:
Sequentially routes requests through multiple models in case of
Selects the best model based on real-time performance metrics.
Distributes traffic between multiple models using predefined weightings.
Chooses the model with the lowest response time for real-time applications.
Combines multiple routing strategies for flexible traffic management.
Fallback routing allows sequential attempts to different model targets in case of failure or unavailability. It ensures robustness by cascading through a list of models based on predefined logic.
{
"model": "router/dynamic",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "What is the formula of a square plot?" }
],
"router": {
"router": "router",
"type": "fallback", // Type: fallback/script/optimized/percentage/latency
"targets": [
{ "model": "openai/gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 },
{ "model": "deepseek/deepseek-chat", "frequency_penalty": 1, "presence_penalty": 0.6 }
]
},
"stream": false
}Optimized routing automatically selects the best model based on real-time performance metrics such as latency, response time, and cost-efficiency.
{
"model": "router/dynamic",
"router": {
"name": "fastest",
"type": "optimized",
"metric": "ttft",
"targets": [
{ "model": "gpt-3.5-turbo", "temperature": 0.8, "max_tokens": 400, "frequency_penalty": 0.5 },
{ "model": "gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 }
]
}
}Here, the request is routed to the model with the lowest Time-to-First-Token (TTFT) among gpt-3.5-turbo and gpt-4o-mini.
Metrics:
Requests – Total number of requests sent to the model.
InputTokens – Number of tokens provided as input to the model.
OutputTokens – Number of tokens generated by the model in response.
TotalTokens – Combined count of input and output tokens.
RequestsDuration – Total duration taken to process requests.
Ttft (Time-to-First-Token) (Default) – Time taken by the model to generate its first token after receiving a request.
LlmUsage – The total computational cost of using the model, often used for cost-based routing.
Percentage-based routing distributes requests between models according to predefined weightings, allowing load balancing, A/B testing, or controlled experimentation with different configurations. Each model can have distinct parameters while sharing the request load.
{
"model": "router/dynamic",
"router": {
"name": "dynamic",
"type": "percentage",
"targets": [
{ "model": "openai/gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 },
{ "model": "openai/gpt-4o-mini", "temperature": 0.8, "max_tokens": 400, "frequency_penalty": 1 }
],
"targets_percentages": [ 70, 30 ]
}
}Latency-based routing selects the model with the lowest response time, ensuring minimal delay for real-time applications like chatbots and interactive AI systems.
{
"model": "router/dynamic",
"router": {
"name": "fastest_latency",
"type": "latency",
"targets": [
{ "model": "openai/gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 },
{ "model": "deepseek/deepseek-chat", "frequency_penalty": 1, "presence_penalty": 0.6 },
{ "model": "gemini/gemini-2.0-flash-exp", "temperature": 0.8, "max_tokens": 400, "frequency_penalty": 0.5 }
]
}
}LangDB AI allows nesting of routing strategies, enabling combinations like fallback within script-based selection. This flexibility helps refine model selection based on dynamic business needs.
{
"model": "router/dynamic",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "What is the formula of a square plot?" }
],
"router": {
"type": "fallback",
"targets": [
{
"model": "router/dynamic",
"router": {
"name": "cheapest_script_execution",
"type": "script",
"script": "const route = ({ models }) => models \
.filter(m => m.inference_provider.provider === 'bedrock' && m.type === 'completions') \
.sort((a, b) => a.price.per_input_token - b.price.per_input_token)[0]?.model;"
}
},
{
"model": "router/dynamic",
"router": {
"name": "fastest",
"type": "optimized",
"metric": "ttft",
"targets": [
{ "model": "gpt-3.5-turbo", "temperature": 0.8, "max_tokens": 400, "frequency_penalty": 0.5 },
{ "model": "gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 }
]
}
},
{ "model": "deepseek/deepseek-chat", "temperature": 0.7, "max_tokens": 300, "frequency_penalty": 1 }
]
},
"stream": false
}Get full visibility into API consumption with cost, speed, and reliability insights to optimize your LLM workflows efficiently.
You can monitor API usage with key insights.
After integrating LangDB into your project, the Analytics Dashboard becomes your central hub for understanding usage.
LangDB’s Analytics Dashboard is segmented into several key panels:
Tracks your total cost consumption across all integrated models.
Enables you to compare costs by provider/model/tags, helping you identify the most cost-effective options for your use cases.
Displays the average duration of requests in milliseconds.
Useful for benchmarking response times and optimizing performance for latency-sensitive applications.
Shows the total number of API calls made.
Helps you analyze usage patterns and allocate resources effectively.
Indicates the average time taken to receive the first token from the API response.
This metric is critical for understanding initial latency.
Measures the throughput of token generation.
High TPS is indicative of efficient processing.
Tracks the average time spent per output token.
Helps in identifying and troubleshooting bottlenecks in model output.
Displays the percentage of failed requests over total requests.
Helps monitor system stability and reliability.
Tracks the total number of failed API requests.
Useful for debugging and troubleshooting failures effectively.
Provides a detailed timeseries view of API usage metrics. Users can filter data by time range and group it by provider, model, or tags to analyze trends over different periods.
# grouby: provider/tag/model
curl --location 'https://api.us-east-1.langdb.ai/analytics' \
--header 'x-project-id: langDBProjectID' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer langDBAPIKey' \
--data '{"start_time_us": , "end_time_us": , "groupBy": ["provider"]}'Example response:
{
"timeseries": [
{
"hour": "2025-01-23 04:00:00",
"total_cost": 0.0006719999999999999,
"total_requests": 2,
"avg_duration": 814.4,
"duration": 814.4,
"duration_p99": 1125.4,
"duration_p95": 1100.0,
"duration_p90": 1068.3,
"duration_p50": 814.4,
"total_duration": 1628.778,
"total_input_tokens": 72,
"total_output_tokens": 38,
"error_rate": 0.0,
"error_request_count": 0,
"avg_ttft": 814.4,
"ttft": 814.4,
"ttft_p99": 1125.4,
"ttft_p95": 1100.0,
"ttft_p90": 1068.3,
"ttft_p50": 814.4,
"tps": 67.54,
"tps_p99": 110.03,
"tps_p95": 107.55,
"tps_p90": 104.45,
"tps_p50": 79.63,
"tpot": 0.04,
"tpot_p99": 0.06,
"tpot_p95": 0.06,
"tpot_p90": 0.06,
"tpot_p50": 0.04,
"tag_tuple": [
"openai"
]
}
]
}Provides aggregated usage metrics, allowing users to get a high-level overview of API consumption and error rates.
# grouby: provider/tag/model
curl --location 'https://api.us-east-1.langdb.ai/analytics/summary' \
--header 'x-project-id: langDBProjectID' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer langDBAPIKey' \
--data '{"start_time_us": , "end_time_us": , "groupBy": ["provider"]} 'Example response:
{
"summary": {
"tag_tuple": [
"togetherai"
],
"total_cost": 0.0015163199999999998,
"total_requests": 8,
"total_duration": 5242.402,
"avg_duration": 655.3,
"duration": 655.3,
"duration_p99": 969.2,
"duration_p95": 962.5,
"duration_p90": 954.1,
"duration_p50": 624.3,
"total_input_tokens": 853,
"total_output_tokens": 200,
"avg_ttft": 655.3,
"ttft": 655.3,
"ttft_p99": 969.2,
"ttft_p95": 962.5,
"ttft_p90": 954.1,
"ttft_p50": 624.3,
"tps": 200.86,
"tps_p99": 336.04,
"tps_p95": 304.95,
"tps_p90": 266.08,
"tps_p50": 186.24,
"tpot": 0.03,
"tpot_p99": 0.04,
"tpot_p95": 0.04,
"tpot_p90": 0.04,
"tpot_p50": 0.03,
"error_rate": 0.0,
"error_request_count": 0
},
}As discussed in User Tracking, we can use filters to retrieve insights based on id, name, or tags.
Available Filters:
user_id: Filter data for a specific user by their unique ID.
user_name: Retrieve usage based on the user’s name.
user_tags: Filter by tags associated with a user (e.g., "websearch", "support").
curl -L \
--request POST \
--url 'https://api.us-east-1.langdb.ai/analytics/summary' \
--header 'Authorization: Bearer langDBAPIKey' \
--header 'X-Project-Id: langDBProjectID' \
--header 'Content-Type: application/json' \
--data '{
"user_id": "123",
"user_name": "mrunmay",
"user_tags": ["websearch", "testings"]
}'Example response:
{
"summary": [
{
"total_cost": 0.00112698,
"total_requests": 4,
"total_duration": 31645.018,
"avg_duration": 7911.3,
"duration": 7911.3,
"duration_p99": 9819.3,
"duration_p95": 9809.0,
"duration_p90": 9796.1,
"duration_p50": 8193.2,
"total_input_tokens": 4429,
"total_output_tokens": 458,
"avg_ttft": 7911.3,
"ttft": 7911.3,
"ttft_p99": 9819.3,
"ttft_p95": 9809.0,
"ttft_p90": 9796.1,
"ttft_p50": 8193.2,
"tps": 154.43,
"tps_p99": 207.79,
"tps_p95": 206.1,
"tps_p90": 203.99,
"tps_p50": 160.85,
"tpot": 0.07,
"tpot_p99": 0.1,
"tpot_p95": 0.09,
"tpot_p90": 0.09,
"tpot_p50": 0.07,
"error_rate": 0.0,
"error_request_count": 0
}
],
"start_time_us": 1737576094363076,
"end_time_us": 1740168094363076
}Stop guessing which model to pick. The Auto Router picks the best one for you—whether you care about cost, speed, or accuracy.
Stop guessing which model to pick. The Auto Router picks the best one for you—whether you care about cost, speed, or accuracy.
Save Costs - Automatically uses cheaper models for simple queries
Get Faster Responses - Routes to the fastest model when speed matters
Guarantee Accuracy - Picks the best model for critical tasks
Handle Scale - No configuration hell, just works
You can also try Auto Router through the LangDB dashboard:
Note: The UI shows only a few router variations. For all available options and advanced configurations, use the API.
Here's what happens behind the scenes when you use Auto Router:
That's it — no config needed. The router classifies the query and picks the best model automatically.
If you already know the query type (e.g., Finance), skip auto-classification with
router/finance:accuracy.
Behind the scenes, the Auto Router uses lightweight classifiers (NVIDIA for complexity, BART for topic) combined with LangDB's routing engine. These decisions are logged in traces so you can inspect why a query was sent to a specific model.
The Auto Router uses a two-stage classification process:
Complexity Classification: Uses NVIDIA's classification model to determine if a query is high or low complexity
Topic Classification: Uses Facebook's BART Large model to identify the query's topic from these categories:
Academia
Finance
Marketing
Maths
Programming
Science
Vision
Writing
Based on these classifications and your chosen optimization strategy, the router automatically selects the best model from your available options.
Perfect for FAQ bots, education apps, and high-volume content generation.
Ideal for finance, medical, legal, and research applications.
Great for real-time assistants, voice bots, and interactive UIs.
Intelligently distributes requests across available models for optimal performance. Works well for most business applications and integrations.
If you already know your query belongs to a specific domain, you can skip classification and directly route to a topic with your chosen optimization mode.
Result:
Skips complexity + topic classification
Directly applies accuracy optimization for the finance topic
Routes to the highest-scoring finance-optimized model
Available topic shortcuts:
router/finance:<mode>
router/writing:<mode>
router/academia:<mode>
router/programming:<mode>
router/science:<mode>
router/vision:<mode>
router/marketing:<mode>
router/maths:<mode>
Where <mode> can be: balanced, accuracy, cost, latency, or throughput.
Quick Decision Guide:
Don't know the type? → Use router/auto
Know the type? → Jump straight with router/<topic>:<mode>
Choose the Right Mode - Match optimization to your use case
Monitor Performance - Use LangDB's analytics to track routing decisions
Combine with Fallbacks - Add fallback models for high availability
Test Different Modes - Experiment to find the best fit
The Auto Router works seamlessly with:
Guardrails - Apply content filtering before routing
MCP Servers - Access external tools and data sources
Response Caching - Cache responses for frequently asked questions
Analytics - Track routing decisions and performance metrics
{
"model": "router/auto",
"messages": [
{
"role": "user",
"content": "What's the capital of France?"
}
]
}router/auto
Classifies complexity + topic. Low-complexity queries go to cheaper models; high-complexity queries go to stronger models. Then applies your optimization strategy.
router/auto:<mode>
Classifies topic only. Ignores complexity and always applies the chosen optimization (cost, accuracy, etc.) for that topic.
router/<topic>:<mode>
Skips classification. Directly routes to the specified topic with the chosen optimization mode.
balanced
Intelligently distributes requests across models for optimal performance
General apps (default)
accuracy
Picks models with best benchmark scores
Research, compliance
cost
Routes to cheapest viable model
Support chatbots, FAQs
latency
Always picks the fastest
Real-time UIs, voice bots
throughput
Distributes across many models
High-volume pipelines
{
"model": "router/auto:cost",
"messages": [
{
"role": "user",
"content": "What are your business hours?"
}
]
}{
"model": "router/auto:accuracy",
"messages": [
{
"role": "user",
"content": "Analyze this financial risk assessment"
}
]
}{
"model": "router/auto:latency",
"messages": [
{
"role": "user",
"content": "What's the weather like today?"
}
]
}{
"model": "router/auto",
"messages": [
{
"role": "user",
"content": "Help me write a product description"
}
]
}{
"model": "router/finance:accuracy",
"messages": [
{
"role": "user",
"content": "Analyze the risk factors in this financial derivative"
}
]
}{
"model": "router/auto",
"router": {
"topic_routing": {
"finance": "cost",
"writing": "latency",
"technical": "accuracy"
}
},
"messages": [
{
"role": "user",
"content": "Calculate the net present value of this investment"
}
]
}





Automatically instrument LangChain chains and agents with LangDB—gain live traces, cost analytics, and latency insights through init().
LangDB provides seamless tracing and observability for LangChain-based applications.
Install the LangDB client with LangChain support:
pip install 'pylangdb[langchain]'export LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'Import and run the initialize before configuring your LangChain/LangGraph:
from pylangdb.langchain import init
# Initialise LangDB
init()# Your existing LangChain code works with proper configuration
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
import os
api_base = "https://api.us-east-1.langdb.ai"
api_key = os.getenv("LANGDB_API_KEY")
project_id = os.getenv("LANGDB_PROJECT_ID")
# Default headers for API requests
default_headers: dict[str, str] = {
"x-project-id": project_id
}
# Initialize OpenAI LLM with LangDB configuratio
llm = ChatOpenAI(
model_name="gpt-4o",
temperature=0.3,
openai_api_base=api_base,
openai_api_key=api_key,
default_headers=default_headers,
)
result = llm.invoke([HumanMessage(content="Hello, LangDB!")])Once LangDB is initialized, all calls to llm, intermediate steps, tool executions, and nested chains are automatically traced and linked under a single session.
Here is a full LangGraph example based on ReAct Agent which uses LangDB Tracing.
Check out the full sample on GitHub: https://github.com/langdb/langdb-samples/tree/main/examples/langchain/langgraph-tracing
Install the libraries using pip
pip install langgraph 'pylangdb[langchain]' langchain_openai geopyexport LANGDB_API_KEY="<your_langdb_api_key>"
export LANGDB_PROJECT_ID="<your_langdb_project_id>"
export LANGDB_API_BASE_URL='https://api.us-east-1.langdb.ai'# Initialize LangDB tracing
from pylangdb.langchain import init
init()
import os
from typing import Annotated, Sequence, TypedDict
from datetime import datetime
# Import required libraries
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage, ToolMessage
from langchain_core.tools import tool
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from geopy.geocoders import Nominatim
from pydantic import BaseModel, Field
import requests
# Initialize the model
def create_model():
"""Create and return the ChatOpenAI model."""
api_base = os.getenv("LANGDB_API_BASE_URL")
api_key = os.getenv("LANGDB_API_KEY")
project_id = os.getenv("LANGDB_PROJECT_ID")
default_headers = {
"x-project-id": project_id,
}
llm = ChatOpenAI(
model_name='openai/gpt-4o', # Choose any model from LangDB
temperature=0.3,
openai_api_base=api_base,
openai_api_key=api_key,
default_headers=default_headers
)
return llm
# Define the agent state
class AgentState(TypedDict):
"""The state of the agent."""
messages: Annotated[Sequence[BaseMessage], add_messages]
number_of_steps: int
# Define the weather tool
class SearchInput(BaseModel):
location: str = Field(description="The city and state, e.g., San Francisco")
date: str = Field(description="The forecasting date in format YYYY-MM-DD")
@tool("get_weather_forecast", args_schema=SearchInput, return_direct=True)
def get_weather_forecast(location: str, date: str) -> dict:
"""
Retrieves the weather using Open-Meteo API for a given location (city) and a date (yyyy-mm-dd).
Returns a dictionary with the time and temperature for each hour.
"""
geolocator = Nominatim(user_agent="weather-app")
location = geolocator.geocode(location)
if not location:
return {"error": "Location not found"}
try:
response = requests.get(
f"https://api.open-meteo.com/v1/forecast?"
f"latitude={location.latitude}&"
f"longitude={location.longitude}&"
"hourly=temperature_2m&"
f"start_date={date}&end_date={date}",
timeout=10
)
response.raise_for_status()
data = response.json()
return {
time: f"{temp}°C"
for time, temp in zip(
data["hourly"]["time"],
data["hourly"]["temperature_2m"]
)
}
except Exception as e:
return {"error": f"Failed to fetch weather data: {str(e)}"}
# Define the nodes
def call_model(state: AgentState) -> dict:
"""Call the model with the current state and return the response."""
model = create_model()
model.bind_tools([get_weather_forecast]
messages = state["messages"]
response = model.invoke(messages)
return {"messages": [response], "number_of_steps": state["number_of_steps"] + 1}
def route_to_tool(state: AgentState) -> str:
"""Determine the next step based on the model's response."""
messages = state["messages"]
last_message = messages[-1]
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
return "call_tool"
return END
# Create the graph
def create_agent():
"""Create and return the LangGraph agent."""
# Create the graph
workflow = StateGraph(AgentState)
workflow.add_node("call_model", call_model)
workflow.add_node("call_tool", ToolNode([get_weather_forecast]))
workflow.set_entry_point("call_model")
workflow.add_conditional_edges(
"call_model",
route_to_tool,
{
"call_tool": "call_tool",
END: END
}
)
workflow.add_edge("call_tool", "call_model")
return workflow.compile()
def main():
agent = create_agent()
query = f"What's the weather in Paris today? Today is {datetime.now().strftime('%Y-%m-%d')}."
initial_state = {
"messages": [HumanMessage(content=query)],
"number_of_steps": 0
}
print(f"Query: {query}")
print("\nRunning agent...\n")
for output in agent.stream(initial_state):
for key, value in output.items():
if key == "__end__":
continue
print(f"\n--- {key.upper()} ---")
if key == "messages":
for msg in value:
if hasattr(msg, 'content'):
print(f"{msg.type}: {msg.content}")
if hasattr(msg, 'tool_calls') and msg.tool_calls:
print(f"Tool Calls: {msg.tool_calls}")
else:
print(value)
if __name__ == "__main__":
main()
Navigate to the parent directory of your agent project and use one of the following commands:
python main.py--- CALL_MODEL ---
{'messages': [AIMessage(content="The weather in Paris on July 1, 2025, is as follows:\n\n- 00:00: 28.1°C\n- 01:00: 27.0°C\n- 02:00: 26.3°C\n- 03:00: 25.7°C\n- 04:00: 25.1°C\n- 05:00: 24.9°C\n- 06:00: 25.8°C\n- 07:00: 27.6°C\n- 08:00: 29.6°C\n- 09:00: 31.7°C\n- 10:00: 33.7°C\n- 11:00: 35.1°C\n- 12:00: 36.3°C\n- 13:00: 37.3°C\n- 14:00: 38.6°C\n- 15:00: 37.9°C\n- 16:00: 38.1°C\n- 17:00: 37.8°C\n- 18:00: 37.3°C\n- 19:00: 35.3°C\n- 20:00: 33.2°C\n- 21:00: 30.8°C\n- 22:00: 28.7°C\n- 23:00: 27.3°C\n\nIt looks like it's going to be a hot day in Paris!", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 319, 'prompt_tokens': 585, 'total_tokens': 904, 'completion_tokens_details': None, 'prompt_tokens_details': None, 'cost': 0.005582999999999999}, 'model_name': 'gpt-4o', 'system_fingerprint': None, 'id': '3bbde343-79e3-4d8f-bd97-b07179ee92c0', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None}, id='run--4fd3896d-1fbd-4c91-9c21-bd6cf3d2949e-0', usage_metadata={'input_tokens': 585, 'output_tokens': 319, 'total_tokens': 904, 'input_token_details': {}, 'output_token_details': {}})], 'number_of_steps': 2}
When you run queries against your agent, LangDB automatically captures detailed traces of all agent interactions:
This guide covered the basics of integrating LangDB with LangGraph using a ReAcT agent example. For more complex scenarios and advanced use cases, check out our comprehensive resources in .
The ID of the thread to retrieve messages from
LangDB project ID
A list of messages for the given thread
GET /threads/{thread_id}/messages HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Accept: */*
A list of messages for the given thread
[
{
"model_name": "gpt-4o-mini",
"thread_id": "123e4567-e89b-12d3-a456-426614174000",
"user_id": "langdb",
"content_type": "Text",
"content": "text",
"content_array": [
"text"
],
"type": "system",
"tool_call_id": "123e4567-e89b-12d3-a456-426614174000",
"tool_calls": "text",
"created_at": "2025-01-29 10:25:00.736000",
"id": "123e4567-e89b-12d3-a456-426614174000"
}
]The ID of the thread for which to retrieve cost information
LangDB project ID
The total cost and token usage for the specified thread
GET /threads/{thread_id}/cost HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Accept: */*
The total cost and token usage for the specified thread
{
"total_cost": 0.022226999999999997,
"total_output_tokens": 171,
"total_input_tokens": 6725
}Register and configure a new LLM under your LangDB project
LangDB Admin Key
my-modelA custom completions model for text and image inputse2e9129b-6661-4eeb-80a2-0c86964974c955f4a12b-74c8-4294-8e4b-537f13fc3861falseopenai-compatiblecompletions0.000010.00003128000["tools"]["text","image"]["text","image"]openai0my-model-v1.2Additional configuration parameters
{"top_k":{"default":0,"description":"Limits the token sampling to only the top K tokens.","min":0,"required":false,"step":1,"type":"int"},"top_p":{"default":1,"description":"Nucleus sampling alternative.","max":1,"min":0,"required":false,"step":0.05,"type":"float"}}Created
POST /admin/models HTTP/1.1
Host: api.xxx.langdb.ai
Authorization: Bearer JWT
X-Admin-Key: text
Content-Type: application/json
Accept: */*
Content-Length: 884
{
"model_name": "my-model",
"description": "A custom completions model for text and image inputs",
"provider_info_id": "e2e9129b-6661-4eeb-80a2-0c86964974c9",
"project_id": "55f4a12b-74c8-4294-8e4b-537f13fc3861",
"public": false,
"request_response_mapping": "openai-compatible",
"model_type": "completions",
"input_token_price": 0.00001,
"output_token_price": 0.00003,
"context_size": 128000,
"capabilities": [
"tools"
],
"input_types": [
"text",
"image"
],
"output_types": [
"text",
"image"
],
"tags": [],
"type_prices": {
"text_generation": 0.00002
},
"mp_price": null,
"owner_name": "openai",
"priority": 0,
"model_name_in_provider": "my-model-v1.2",
"parameters": {
"top_k": {
"default": 0,
"description": "Limits the token sampling to only the top K tokens.",
"min": 0,
"required": false,
"step": 1,
"type": "int"
},
"top_p": {
"default": 1,
"description": "Nucleus sampling alternative.",
"max": 1,
"min": 0,
"required": false,
"step": 0.05,
"type": "float"
}
}
}Created
{
"id": "55f4a12b-74c8-4294-8e4b-537f13fc3861",
"model_name": "my-model",
"description": "A custom completions model for text and image inputs",
"provider_info_id": "e2e9129b-6661-4eeb-80a2-0c86964974c9",
"model_type": "completions",
"input_token_price": "0.00001",
"output_token_price": "0.00003",
"context_size": 128000,
"capabilities": [
"tools"
],
"input_types": [
"text",
"image"
],
"output_types": [
"text",
"image"
],
"tags": [],
"type_prices": null,
"mp_price": null,
"model_name_in_provider": "my-model-v1.2",
"owner_name": "openai",
"priority": 0,
"parameters": {
"top_k": {
"default": 0,
"description": "Limits the token sampling to only the top K tokens.",
"min": 0,
"required": false,
"step": 1,
"type": "int"
},
"top_p": {
"default": 1,
"description": "An alternative to sampling with temperature.",
"max": 1,
"min": 0,
"required": false,
"step": 0.05,
"type": "float"
}
}
}Returns the pricing details for LangDB services.
Successful retrieval of pricing information
GET /pricing HTTP/1.1
Host: api.us-east-1.langdb.ai
Accept: */*
Successful retrieval of pricing information
{
"model": "gpt-3.5-turbo-0125",
"provider": "openai",
"price": {
"per_input_token": 0.5,
"per_output_token": 1.5,
"valid_from": null
},
"input_formats": [
"text"
],
"output_formats": [
"text"
],
"capabilities": [
"tools"
],
"type": "completions",
"limits": {
"max_context_size": 16385
}
}Set custom pricing for models imported from providers like Bedrock, Azure, Vertex that do not have built-in pricing
UUID of the project
25a0b7d9-86cf-448d-8395-66e9073d876fRequest body for setting custom prices on imported models
Custom prices set successfully
POST /projects/{project_id}/custom_prices HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
Content-Type: application/json
Accept: */*
Content-Length: 88
{
"bedrock/twelvelabs.pegasus-1-2-v1:0": {
"per_input_token": 1.23,
"per_output_token": 2.12
}
}Custom prices set successfully
{
"bedrock/ai21.jamba-1-5-large-v1:0": {
"per_input_token": 1.23,
"per_output_token": 2.12
}
}

Enforce safety, compliance, and quality with LangDB guardrails—moderate content, validate responses, and detect security risks.
LangDB allow developers to enforce specific constraints and checks on their LLM calls, ensuring safety, compliance, and quality control.
Guardrails currently support request validation and logging, ensuring structured oversight of LLM interactions.
These guardrails include:
Content Moderation: Detects and filters harmful or inappropriate content (e.g., toxicity detection, sentiment analysis).
Security Checks: Identifies and mitigates security risks (e.g., PII detection, prompt injection detection).
Compliance Enforcement: Ensures adherence to company policies and factual accuracy (e.g., policy adherence, factual accuracy).
Response Validation: Validates response format and structure (e.g., word count, JSON schema, regex patterns).
Guardrails can be configured via the UI or API, providing flexibility for different use cases.
When a guardrail blocks an input or output, the system returns a structured error response. Below are some example responses for different scenarios:
{
"id": "",
"object": "chat.completion",
"created": 0,
"model": "",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Input rejected by guard",
"tool_calls": null,
"refusal": null,
"tool_call_id": null
},
"finish_reason": "rejected"
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0,
"cost": 0.0
}
}{
"id": "5ef4d8b1-f700-46ca-8439-b537f58f7dc6",
"object": "chat.completion",
"created": 1741865840,
"model": "gpt-4o-mini",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Output rejected by guard",
"tool_calls": null,
"refusal": null,
"tool_call_id": null
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 21,
"completion_tokens": 40,
"total_tokens": 61,
"cost": 0.000032579999999999996
}
}It is important to note that guardrails cannot be applied to streaming outputs.
LangDB provides prebuilt templates to enforce various constraints on LLM responses. These templates cover areas such as content moderation, security, compliance, and validation.
The following table provides quick access to each guardrail template:
Detects and filters toxic or harmful content.
Validates responses against a user-defined JSON schema.
Detects mentions of competitor names or products.
Identifies personally identifiable information in responses.
Detects attempts to manipulate the AI through prompt injections.
Ensures responses align with company policies.
Validates responses against specified regex patterns.
Ensures responses meet specified word count requirements.
Evaluates sentiment to ensure appropriate tone.
Checks if responses are in allowed languages.
Ensures responses stay on specified topics.
Validates that responses contain factually accurate information.
content-toxicity)Detects and filters out toxic, harmful, or inappropriate content.
validation-json-schema)Validates responses against a user-defined JSON schema.
schema
object
Custom JSON schema to validate against (replace with your own schema)
Required
content-competitor-mentions)Detects mentions of competitor names or products in LLM responses.
competitors
array
List of competitor names.
["company1", "company2"]
match_partial
boolean
Whether to match partial names.
true
case_sensitive
boolean
Whether matching should be case sensitive
false
security-pii-detection)Detects personally identifiable information (PII) in responses.
pii_types
array
Types of PII to detect.
["email", "phone", "ssn", "credit_card"]
redact
boolean
Whether to redact detected PII.
false
security-prompt-injection)Identifies prompt injection attacks attempting to manipulate the AI.
threshold
number
Confidence threshold for injection detection.
Required
detection_patterns
array
Common patterns used in prompt injection attacks.
["Ignore previous instructions", "Forget your training", "Tell me your prompt"]
evaluation_criteria
array
Criteria used for detection.
["Attempts to override system instructions", "Attempts to extract system prompt information", "Attempts to make the AI operate outside its intended purpose"]
compliance-company-policy)Ensures that responses align with predefined company policies.
embedding_model
string
Model used for text embedding.
text-embedding-ada-002
threshold
number
Similarity threshold for compliance.
Required
dataset
object
Example dataset for compliance checking.
Contains predefined examples
validation-regex-pattern)Validates responses against specific regex patterns.
patterns
array
Model List of regex patterns.
["^[A-Za-z0-9\s.,!?]+$"]
match_type
string
Whether all, any, or none of the patterns must match.
"all"
validation-word-count)Ensures responses meet specified word count requirements.
min_words
number
Model List of regex patterns.
10
max_words
number
Whether all, any, or none of the patterns must match.
500
count_method
string
Method for word counting.
split
content-sentiment-analysis)Evaluates the sentiment of responses to ensure appropriate tone.
allowed_sentiments
array
Allowed sentiment categories.
["positive", "neutral"]
threshold
number
Confidence threshold for sentiment detection.
0.7
content-language-validation)Checks if responses are in allowed languages.
allowed_languages
array
List of allowed languages.
["english"]
threshold
number
Confidence threshold for language detection.
0.9
content-topic-adherence)Ensures responses stay on specified topics.
allowed_topics
array
List of allowed topics.
["Product information", "Technical assistance"]
forbidden_topics
array
List of forbidden topics.
["politics", "religion"]
threshold
number
Confidence threshold for topic detection.
0.7
content-factual-accuracy)Validates that responses contain factually accurate information.
reference_facts
array
List of reference facts.
[]
threshold
number
Confidence threshold for factuality assessment.
0.8
evaluation_criteria
array
Criteria used to assess factual accuracy.
["Contains verifiable information", "Avoids speculative claims"]
LangDB project ID
Start time in microseconds.
1693062345678End time in microseconds.
1693082345678Time period for filtering data. If provided, start_time and end_time will be ignored.
last_monthPossible values: Successful response
POST /analytics HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 23
{
"period": "last_month"
}Successful response
{
"timeseries": [
{
"hour": "2025-02-20 18:00:00",
"total_cost": 12.34,
"total_requests": 1000,
"avg_duration": 250.5,
"duration": 245.7,
"duration_p99": 750.2,
"duration_p95": 500.1,
"duration_p90": 400.8,
"duration_p50": 200.3,
"total_duration": 1,
"total_input_tokens": 1,
"total_output_tokens": 1,
"error_rate": 1,
"error_request_count": 1,
"avg_ttft": 1,
"ttft": 1,
"ttft_p99": 1,
"ttft_p95": 1,
"ttft_p90": 1,
"ttft_p50": 1,
"tps": 1,
"tps_p99": 1,
"tps_p95": 1,
"tps_p90": 1,
"tps_p50": 1,
"tpot": 0.85,
"tpot_p99": 1.5,
"tpot_p95": 1.2,
"tpot_p90": 1,
"tpot_p50": 0.75,
"tag_tuple": [
"text"
]
}
],
"start_time": 1,
"end_time": 1
}LangDB project ID
16930623456781693082345678Time period for filtering data. If provided, start_time and end_time will be ignored.
last_monthPossible values: ["provider"]Successful response
POST /analytics/summary HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 46
{
"period": "last_month",
"groupBy": [
"provider"
]
}Successful response
{
"summary": [
{
"tag_tuple": [
"openai",
"gpt-4"
],
"total_cost": 156.78,
"total_requests": 5000,
"total_duration": 1250000,
"avg_duration": 250,
"duration": 245.5,
"duration_p99": 750,
"duration_p95": 500,
"duration_p90": 400,
"duration_p50": 200,
"total_input_tokens": 100000,
"total_output_tokens": 50000,
"avg_ttft": 100,
"ttft": 98.5,
"ttft_p99": 300,
"ttft_p95": 200,
"ttft_p90": 150,
"ttft_p50": 80,
"tps": 10.5,
"tps_p99": 20,
"tps_p95": 15,
"tps_p90": 12,
"tps_p50": 8,
"tpot": 0.85,
"tpot_p99": 1.5,
"tpot_p95": 1.2,
"tpot_p90": 1,
"tpot_p50": 0.75,
"error_rate": 1,
"error_request_count": 1
}
],
"start_time": 1,
"end_time": 1
}LangDB project ID
1693062345678End time in microseconds.
1693082345678Time period for filtering data. If provided, start_time and end_time will be ignored.
last_monthPossible values: OK
POST /usage/total HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 23
{
"period": "last_month"
}OK
{
"models": [
{
"provider": "openai",
"model_name": "gpt-4o",
"total_input_tokens": 3196182,
"total_output_tokens": 74096,
"total_cost": 10.4776979999,
"cost_per_input_token": 3,
"cost_per_output_token": 12
}
],
"total": {
"total_input_tokens": 4181386,
"total_output_tokens": 206547,
"total_cost": 11.8904386859
},
"period_start": 1737504000,
"period_end": 1740120949
}LangDB project ID
1693062345678The granularity of the returned usage data.
hourPossible values: Successful response
POST /usage/models HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 65
{
"start_time_us": 1693062345678,
"end_time_us": 1,
"min_unit": "hour"
}Successful response
{
"models": [
{
"hour": "2025-02-15 09:00:00",
"provider": "openai",
"model_name": "gpt-4o",
"total_input_tokens": 451235,
"total_output_tokens": 2553,
"total_cost": 1.3843410000000005
}
],
"period_start": 1737504000000000,
"period_end": 1740121147931000
}
LangDB project ID
ID of the model to use. This can be either a specific model ID or a virtual model identifier.
gpt-4oSampling temperature.
0.8Nucleus sampling probability.
The maximum number of tokens that can be generated in the chat completion.
How many chat completion choices to generate for each input message.
1Up to 4 sequences where the API will stop generating further tokens.
Penalize new tokens based on whether they appear in the text so far.
Penalize new tokens based on their existing frequency in the text so far.
Whether to return log probabilities of the output tokens.
The number of most likely tokens to return at each position, for which the log probabilities are returned. Requires logprobs=true.
If specified, the backend will make a best effort to return deterministic results.
Format for the model's response.
Controls which (if any) tool is called by the model. none means the model will not call any tool and instead generates a message. auto means the model can pick between generating a message or calling one or more tools. required means the model must call one or more tools.
Whether to enable parallel function calling during tool use.
trueWhether to stream back partial progress.
falseDeprecated. This field is being replaced by safety_identifier and prompt_cache_key.
Use prompt_cache_key to maintain caching optimizations. A stable identifier for your end-users
was previously used to boost cache hit rates by better bucketing similar requests and to help detect and prevent abuse.
Stable identifier for your end-users, used to help detect and prevent abuse. Prefer this over user.
For caching optimization, combine with prompt_cache_key.
Used to cache responses for similar requests to optimize cache hit rates. LangDB supports prompt caching; see https://docs.langdb.ai/features/prompt-caching. Can be used instead of the user field for cache bucketing.
OK
POST /v1/chat/completions HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 859
{
"model": "router/dynamic",
"messages": [
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
],
"temperature": 0.8,
"max_tokens": 1000,
"top_p": 0.9,
"frequency_penalty": 0.1,
"presence_penalty": 0.2,
"stream": false,
"response_format": "json_object",
"mcp_servers": [
{
"server_url": "wss://your-mcp-server.com/ws?config=your_encoded_config",
"type": "ws"
}
],
"router": {
"type": "conditional",
"routes": [
{
"conditions": {
"all": [
{
"extra.user.tier": {
"$eq": "premium"
}
}
]
},
"name": "premium_user",
"targets": {
"$any": [
"openai/gpt-4.1-mini",
"xai/grok-4",
"anthropic/claude-sonnet-4"
],
"filter": {
"error_rate": {
"$lt": 0.01
}
},
"sort_by": "ttft",
"sort_order": "min"
}
},
{
"name": "basic_user",
"targets": "openai/gpt-4.1-nano"
}
]
},
"extra": {
"guards": [
"word_count_validator_bd4bdnun",
"toxicity_detection_4yj4cdvu"
],
"user": {
"id": "7",
"name": "mrunmay",
"tier": "premium",
"tags": [
"coding",
"software"
]
}
}
}OK
{
"id": "text",
"choices": [
{
"finish_reason": "stop",
"index": 1,
"message": {
"role": "assistant",
"content": "text",
"tool_calls": [
{
"id": "text",
"type": "function",
"function": {
"name": "text",
"arguments": "text"
}
}
],
"function_call": {
"name": "text",
"arguments": "text"
}
},
"logprobs": {
"content": [
{
"token": "text",
"logprob": 1
}
],
"refusal": [
{
"token": "text",
"logprob": 1
}
]
}
}
],
"created": 1,
"model": "text",
"system_fingerprint": "text",
"object": "chat.completion",
"usage": {
"prompt_tokens": 1,
"completion_tokens": 1,
"total_tokens": 1,
"prompt_tokens_details": {
"cached_tokens": 1,
"cache_creation_tokens": 1,
"audio_tokens": 1
},
"completion_tokens_details": {
"reasoning_tokens": 1,
"accepted_prediction_tokens": 1,
"rejected_prediction_tokens": 1,
"audio_tokens": 1
},
"cost": 1
}
}Creates an embedding vector representing the input text or token arrays.
ID of the model to use for generating embeddings.
text-embedding-ada-002The text to embed.
Array of text strings to embed.
The format to return the embeddings in.
floatPossible values: The number of dimensions the resulting embeddings should have.
1536Successful response with embeddings
POST /v1/embeddings HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
Content-Type: application/json
Accept: */*
Content-Length: 136
{
"input": "The food was delicious and the waiter was kind.",
"model": "text-embedding-ada-002",
"encoding_format": "float",
"dimensions": 1536
}Successful response with embeddings
{
"data": [
{
"embedding": [
1
],
"index": 1
}
],
"model": "text",
"usage": {
"prompt_tokens": 1,
"total_tokens": 1
}
}threshold
number
Confidence threshold for toxicity detection.
Required
categories
array
Categories of toxicity to detect.
["hate", "harassment", "violence", "self-harm", "sexual", "profanity"]
evaluation_criteria
array
Criteria used for toxicity evaluation.
["Hate speech", "Harassment", "Violence", "Self-harm", "Sexual content", "Profanity"]
Use LangDB’s Python SDK to generate completions, monitor API usage, retrieve analytics, and evaluate LLM workflows efficiently.
LangDB exposes two complementary capabilities:
Chat Completions Client – Call LLMs using the LangDb Python client. This works as a drop-in replacement for openai.ChatCompletion while adding automatic usage, cost and latency reporting.
Agent Tracing – Instrument your existing AI framework (ADK, LangChain, CrewAI, etc.) with a single init() call. All calls are routed through the LangDB collector and are enriched with additional metadata regarding the framework is visible on the LangDB dashboard.
Note: Always initialize LangDB before importing any framework-specific classes to ensure proper instrumentation.
Example Trace Screenshot
LangDB uses intelligent monkey patching to instrument your AI frameworks at runtime:
Set your credentials (or pass them directly to the init() function):
Get Messages
Retrieve messages from a specific thread:
Get Thread Cost
Get cost and token usage information for a thread:
Get analytics data for specific tags:
All init() functions accept the same optional parameters:
Thread ID: Maintains consistent session identifiers across agent calls
Run ID: Unique identifier for each execution trace
Invocation Tracking: Tracks the sequence of agent invocations
State Persistence: Maintains context across callbacks and sub-agent interactions
OpenTelemetry Integration: Uses OpenTelemetry for standardized tracing
Attribute Propagation: Automatically propagates LangDB-specific attributes
Span Correlation: Links related spans across different agents and frameworks
Custom Exporters: Supports multiple export formats (OTLP, Console)
Each framework has a simple init() function that handles all necessary setup:
langdb.adk.init(): Patches Google ADK Agent class with LangDB callbacks
langdb.openai.init(): Initializes OpenAI agents tracing
langdb.langchain.init(): Initializes LangChain tracing
langdb.crewai.init(): Initializes CrewAI tracing
langdb.agno.init(): Initializes Agno tracing
All init functions accept optional parameters for custom configuration (collector_endpoint, api_key, project_id)
Missing API Key: Ensure LANGDB_API_KEY and LANGDB_PROJECT_ID are set
Tracing Not Working: Check that initialization functions are called before creating agents
Network Issues: Verify collector endpoint is accessible
Framework Conflicts: Initialize LangDB integration before other instrumentation
pip install pylangdb[client]from pylangdb.client import LangDb
# Initialize LangDB client
client = LangDb(api_key="your_api_key", project_id="your_project_id")
# Simple chat completion
resp = client.chat.completions.create(
model="openai/gpt-4o-mini",
messages=[{"role": "user", "content": "Hello!"}]
)
print(resp.choices[0].message.content)# Install the package with Google ADK support
pip install pylangdb[adk]# Import and initialize LangDB tracing
# First initialize LangDB before defining any agents
from pylangdb.adk import init
init()
import datetime
from zoneinfo import ZoneInfo
from google.adk.agents import Agent
def get_weather(city: str) -> dict:
if city.lower() != "new york":
return {"status": "error", "error_message": f"Weather information for '{city}' is not available."}
return {"status": "success", "report": "The weather in New York is sunny with a temperature of 25 degrees Celsius (77 degrees Fahrenheit)."}
def get_current_time(city: str) -> dict:
if city.lower() != "new york":
return {"status": "error", "error_message": f"Sorry, I don't have timezone information for {city}."}
tz = ZoneInfo("America/New_York")
now = datetime.datetime.now(tz)
return {"status": "success", "report": f'The current time in {city} is {now.strftime("%Y-%m-%d %H:%M:%S %Z%z")}'}
root_agent = Agent(
name="weather_time_agent",
model="gemini-2.0-flash",
description=("Agent to answer questions about the time and weather in a city." ),
instruction=("You are a helpful agent who can answer user questions about the time and weather in a city."),
tools=[get_weather, get_current_time],
)Google ADK
pip install pylangdb[adk]
from pylangdb.adk import init
Automatic sub-agent discovery
OpenAI
pip install pylangdb[openai]
from pylangdb.openai import init
Custom model provider support and Run Tracing
LangChain
pip install pylangdb[langchain]
from pylangdb.langchain import init
Automatic chain tracing
CrewAI
pip install pylangdb[crewai]
from pylangdb.crewai import init
Multi-agent crew tracing
Agno
pip install pylangdb[agno]
from pylangdb.agno import init
Tool usage tracing, model interactions
# For client library functionality (chat completions, analytics, etc.)
pip install pylangdb[client]
# For framework tracing - install specific framework extras
pip install pylangdb[adk] # Google ADK tracing
pip install pylangdb[openai] # OpenAI agents tracing
pip install pylangdb[langchain] # LangChain tracing
pip install pylangdb[crewai] # CrewAI tracing
pip install pylangdb[agno] # Agno tracingexport LANGDB_API_KEY="your-api-key"
export LANGDB_PROJECT_ID="your-project-id"from pylangdb import LangDb
# Initialize with API key and project ID
client = LangDb(api_key="your_api_key", project_id="your_project_id")messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Say hello!"}
]
response = client.completion(
model="gemini-1.5-pro-latest",
messages=messages,
temperature=0.7,
max_tokens=100
)messages = client.get_messages(thread_id="your_thread_id")
# Access message details
for message in messages:
print(f"Type: {message.type}")
print(f"Content: {message.content}")
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"Tool: {tool_call.function.name}")usage = client.get_usage(thread_id="your_thread_id")
print(f"Total cost: ${usage.total_cost:.4f}")
print(f"Input tokens: {usage.total_input_tokens}")
print(f"Output tokens: {usage.total_output_tokens}")# Get raw analytics data
analytics = client.get_analytics(
tags="model1,model2",
start_time_us=None, # Optional: defaults to 24 hours ago
end_time_us=None # Optional: defaults to current time
)
# Get analytics as a pandas DataFrame
df = client.get_analytics_dataframe(
tags="model1,model2",
start_time_us=None,
end_time_us=None
)df = client.create_evaluation_df(thread_ids=["thread1", "thread2"])
print(df.head())models = client.list_models()
print(models)from pylangdb.adk import init
# Monkey-patch the client for tracing
init()
# Import your agents after initializing tracing
from google.adk.agents import Agent
from travel_concierge.sub_agents.booking.agent import booking_agent
from travel_concierge.sub_agents.in_trip.agent import in_trip_agent
from travel_concierge.sub_agents.inspiration.agent import inspiration_agent
from travel_concierge.sub_agents.planning.agent import planning_agent
from travel_concierge.sub_agents.post_trip.agent import post_trip_agent
from travel_concierge.sub_agents.pre_trip.agent import pre_trip_agent
from travel_concierge.tools.memory import _load_precreated_itinerary
root_agent = Agent(
model="openai/gpt-4.1",
name="root_agent",
description="A Travel Conceirge using the services of multiple sub-agents",
instruction="Instruct the travel concierge to plan a trip for the user.",
sub_agents=[
inspiration_agent,
planning_agent,
booking_agent,
pre_trip_agent,
in_trip_agent,
post_trip_agent,
],
before_agent_callback=_load_precreated_itinerary,
)import uuid
import os
# Import LangDB tracing
from pylangdb.openai import init
# Initialize tracing
init()
# Import agent components
from agents import (
Agent,
Runner,
set_default_openai_client,
RunConfig,
ModelProvider,
Model,
OpenAIChatCompletionsModel
)
# Configure OpenAI client with environment variables
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key=os.environ.get("LANGDB_API_KEY"),
base_url=os.environ.get("LANGDB_API_BASE_URL"),
default_headers={
"x-project-id": os.environ.get("LANGDB_PROJECT_ID")
}
)
set_default_openai_client(client)
# Create a custom model provider
class CustomModelProvider(ModelProvider):
def get_model(self, model_name: str | None) -> Model:
return OpenAIChatCompletionsModel(model=model_name, openai_client=client)
CUSTOM_MODEL_PROVIDER = CustomModelProvider()
agent = Agent(
name="Math Tutor",
model="gpt-4.1",
instruction="You are a math tutor who can help students with their math homework.",
)
group_id = str(uuid.uuid4())
# Use the model provider with a unique group_id for tracing
async def run_agent():
response = await Runner.run(
triage_agent,
input="Hello World",
run_config=RunConfig(
model_provider=CUSTOM_MODEL_PROVIDER, # Inject custom model provider
group_id=group_id # Link all steps to the same trace
)
)
print(response.final_output)
# Run the async function with asyncio
asyncio.run(run_agent())import os
from pylangdb.langchain import init
init()
# Get environment variables for configuration
api_base = os.getenv("LANGDB_API_BASE_URL")
api_key = os.getenv("LANGDB_API_KEY")
if not api_key:
raise ValueError("Please set the LANGDB_API_KEY environment variable")
project_id = os.getenv("LANGDB_PROJECT_ID")
# Default headers for API requests
default_headers: dict[str, str] = {
"x-project-id": project-id
}
# Your existing LangChain code works with proper configuration
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
# Initialize OpenAI LLM with proper configuration
llm = ChatOpenAI(
model_name="gpt-4",
temperature=0.3,
openai_api_base=api_base,
openai_api_key=api_key,
default_headers=default_headers,
)
result = llm.invoke([HumanMessage(content="Hello, LangChain!")])import os
from crewai import Agent, Task, Crew, LLM
from dotenv import load_dotenv
load_dotenv()
# Import and initialize LangDB tracing
from pylangdb.crewai import init
# Initialize tracing before importing or creating any agents
init()
# Initialize API credentials
api_key = os.environ.get("LANGDB_API_KEY")
api_base = os.environ.get("LANGDB_API_BASE_URL")
project_id = os.environ.get("LANGDB_PROJECT_ID")
# Create LLM with proper headers
llm = LLM(
model="gpt-4",
api_key=api_key,
base_url=api_base,
extra_headers={
"x-project-id": project_id
}
)
# Create and use your CrewAI components as usual
# They will be automatically traced by LangDB
researcher = Agent(
role="researcher",
goal="Research the topic thoroughly",
backstory="You are an expert researcher",
llm=llm,
verbose=True
)
task = Task(
description="Research the given topic",
agent=researcher
)
crew = Crew(agents=[researcher], tasks=[task])
result = crew.kickoff()import os
from agno.agent import Agent
from agno.tools.duckduckgo import DuckDuckGoTools
# Import and initialize LangDB tracing
from pylangdb.agno import init
init()
# Import LangDB model after initializing tracing
from agno.models.langdb import LangDB
# Create agent with LangDB model
agent = Agent(
name="Web Agent",
role="Search the web for information",
model=LangDB(
id="openai/gpt-4",
base_url=os.getenv("LANGDB_API_BASE_URL") + '/' + os.getenv("LANGDB_PROJECT_ID") + '/v1',
api_key=os.getenv("LANGDB_API_KEY"),
project_id=os.getenv("LANGDB_PROJECT_ID"),
),
tools=[DuckDuckGoTools()],
instructions="Answer questions using web search",
show_tool_calls=True,
markdown=True,
)
# Use the agent
response = agent.run("What is LangDB?")LANGDB_API_KEY
Your LangDB API key
Required
LANGDB_PROJECT_ID
Your LangDB project ID
Required
LANGDB_API_BASE_URL
LangDB API base URL
https://api.us-east-1.langdb.ai
LANGDB_TRACING_BASE_URL
Tracing collector endpoint
https://api.us-east-1.langdb.ai:4317
LANGDB_TRACING
Enable/disable tracing
true
LANGDB_TRACING_EXPORTERS
Comma-separated list of exporters
otlp, console
from langdb.openai import init
init(
collector_endpoint='https://api.us-east-1.langdb.ai:4317',
api_key="langdb-api-key",
project_id="langdb-project-id"
)