Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Run LangDB AI Gateway locally.
LangDB AI gateway is available as an open-source repo that you can configure locally. Own your LLM data and route to 250+ models.
Here is the link to the repo - https://github.com/langdb/ai-gateway
Make your first request
# Chat completion with GPT-4
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [{"role": "user", "content": "What is the capital of France?"}]
}'
# Or try Claude
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "claude-3-opus",
"messages": [
{"role": "user", "content": "What is the capital of France?"}
]
}'The gateway provides the following OpenAI-compatible endpoints:
POST /v1/chat/completions - Chat completions
GET /v1/models - List available models
POST /v1/embeddings - Generate embeddings
POST /v1/images/generations - Generate images
LangDB allows advanced configuration options to customize its functionality. The three main configuration areas are:
Limits – Control API usage with rate limiting and cost control.
Routing – Define how requests are routed across multiple LLM providers.
Observability – Enable logging and tracing to monitor API performance.
These configurations can be set up using a configuration file (config.yaml) or overridden via command line options.
Download the sample configuration from our repo.
Copy the example config file:
curl -sL https://raw.githubusercontent.com/langdb/ai-gateway/main/config.sample.yaml -o config.sample.yaml
cp config.sample.yaml config.yamlCommand line options will override corresponding config file settings when both are specified.
Visit for more details.
Configure your tracing data and store them in Clickhouse
The gateway supports OpenTelemetry tracing with ClickHouse as the storage backend. All traces are stored in the langdb.traces table.
Create the traces table in ClickHouse:
# Create langdb database if it doesn't exist
clickhouse-client --query "CREATE DATABASE IF NOT EXISTS langdb"
# Import the traces table schema
clickhouse-client --query "$(cat sql/traces.sql)"Enable tracing by providing the ClickHouse URL when running the server:
ai-gateway serve --clickhouse-url "clickhouse://localhost:9000"Or in config.yaml:
clickhouse:
url: "http://localhost:8123"Traces are stored in the langdb.traces table. Example query:
-- Get recent traces
SELECT
trace_id,
operation_name,
start_time_us,
finish_time_us,
(finish_time_us - start_time_us) as duration_us
FROM langdb.traces
WHERE finish_date >= today() - 1
ORDER BY finish_time_us DESC
LIMIT 10;LangDB APIs can be called directly within ClickHouse. Check out our UDF documentation to learn how to use LLMs in SQL queries.
For a complete setup, including ClickHouse for analytics and tracing, follow these steps:
Start the services using Docker Compose:
docker-compose up -dThis will start:
ClickHouse server on ports 8123 (HTTP)
All necessary configurations loaded from docker/clickhouse/server/config.d
Build and run the gateway:
ai-gateway runThe gateway will now be running with full analytics and logging capabilities, storing data in ClickHouse.
Connect to open-source models using Ollama or vLLM with LangDB AI Gateway.
LangDB AI Gateway supports connecting to open-source models through providers like Ollama and vLLM. This allows you to use locally hosted models while maintaining the same OpenAI-compatible API interface.
To use Ollama or vLLM, you need to provide a list of models with their endpoints. By default, ai-gateway loads models from ~/.langdb/models.yaml. You can define your models there in the following format:
- model: gpt-oss
model_provider: ollama
inference_provider:
provider: ollama
model_name: gpt-oss
endpoint: https://my-ollama-server.localhost
price:
per_input_token: 0.0
per_output_token: 0.0
input_formats:
- text
output_formats:
- text
limits:
max_context_size: 128000
capabilities: ['tools']
type: completions
description: OpenAI's open-weight models designed for powerful reasoning, agentic tasks, and versatile developer use cases.model
The model identifier used in API requests
Yes
model_provider
The provider type (e.g., ollama, vllm)
Yes
inference_provider
Provider-specific configuration
Yes
price
Token pricing (set to 0.0 for local models)
Yes
input_formats
Supported input formats
Yes
output_formats
Supported output formats
Yes
limits
Model limitations (context size, etc.)
Yes
capabilities
Model capabilities array (e.g., ['tools'] for function calling)
Yes
type
Model type (e.g., completions)
Yes
description
Human-readable model description
Yes
Once configured, you can use your OSS models through the standard OpenAI-compatible API:
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss",
"messages": [{"role": "user", "content": "What is the capital of France?"}]
}'Provider: ollama
Endpoint: URL to your Ollama server
Model Name: The model name as configured in Ollama
Provider: vllm
Endpoint: URL to your vLLM server
Model Name: The model name as configured in vLLM
Local Development: Use localhost or 127.0.0.1 for local Ollama/vLLM instances
Production: Use proper domain names or IP addresses for remote instances
Security: Ensure your OSS model endpoints are properly secured
Performance: Consider the network latency between ai-gateway and your model servers
Monitoring: Use the observability features to monitor OSS model performance
API Reference for LangDB
Apply cost control using configuration.
Cost control helps manage API spending by setting daily, monthly, or total cost limits. Configure cost limits using:
# Set daily and monthly limits
ai-gateway serve \
--cost-daily 100.0 \
--cost-monthly 1000.0 \
--cost-total 5000.0Or in config.yaml:
cost_control:
daily: 100.0 # $100 per day
monthly: 1000.0 # $1000 per month
total: 5000.0 # $5000 totalWhen a cost limit is reached, the API will return a 429 response indicating the limit has been exceeded.
Prevents overspending: Ensures budgets are adhered to.
Optimizes usage: Encourages efficient API consumption.
Configure dynamic routing to manage LLM traffic intelligently with fallback, script, and latency strategies in LangDB.
LangDB AI Gateway enables sophisticated routing strategies for LLM requests. You can optimize AI traffic by implementing fallback routing, script-based routing, and latency-based routing.
Self hosted option enables routing through configuration. Checkout the full for more details.
Example Configuration:
This configuration allows multiple targets with specific parameters, ensuring that requests are handled efficiently.
{
"model": "router/dynamic",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "What is the formula of a square plot?" }
],
"router": {
"router": "router",
"type": "fallback",
"targets": [
{ "model": "openai/gpt-4o-mini", "temperature": 0.9, "max_tokens": 500, "top_p": 0.9 },
{ "model": "deepseek/deepseek-chat", "frequency_penalty": 1, "presence_penalty": 0.6 }
]
},
"stream": false
}Apply rate limiting, cost control and more.
Rate limiting is an essential mechanism to prevent API abuse by controlling the number of requests allowed within a specific time frame. You can configure rate limits by setting hourly, daily and monthly total limits
This ensures fair usage and helps maintain system performance and stability.
# Limit to 1000 requests per hour
ai-gateway serve \
--rate-hourly 1000
--rate-daily 1000
--rate-monthly 1000Or in config.yaml:
rate_limit:
hourly: 100
daily: 1000
monthly: 10000When a rate limit is exceeded, the API will return a 429 (Too Many Requests) response.
Prevents excessive LLM API usage: Controls the number of requests per user to avoid resource exhaustion.
Optimizes model inference efficiency: Ensures that LLM requests are processed smoothly without congestion.
Leveraging AI functions directly in your Clickhouse environment
langdb_udf adds support for AI operations directly within ClickHouse through User Defined Functions (UDFs). This enables running AI completions and embeddings natively in your SQL queries. You can access 250+ models directly in Clickhouse.
Check the full list of models supported here
You can find the full instructions in our AI Gateway repository.
ai_completions: Generate AI completions from various models
ai_embed: Create embeddings from text
LangDB UDFs are particularly powerful for running LLM-based evaluations and analysis directly within your ClickHouse environment:
Native Integration: Run AI operations directly in SQL queries without data movement
Batch Processing: Efficiently process and analyze large datasets with LLMs
Real-time Analysis: Perform content moderation, sentiment analysis, and other AI tasks as part of your data pipeline
Model Comparison: Easily compare results across different LLM models in a single query
Scalability: Leverage ClickHouse's distributed architecture for parallel AI processing
Get your LangDB credentials:
Sign up at LangDB
Get your LANGDB_PROJECT_ID and LANGDB_API_KEY
Download the latest landb_udf binary
Set up environment variables:
export LANGDB_PROJECT_ID=your_project_id
export LANGDB_API_KEY=your_api_key# Clone the repository
git clone [email protected]:langdb/ai-gateway.git
cd ai-gateway
# Create directory for ClickHouse user scripts
mkdir -p docker/clickhouse/user_scripts
# Download the latest UDF
curl -sL https://github.com/langdb/ai-gateway/releases/download/0.1.0/langdb_udf \
-o docker/clickhouse/user_scripts/langdb_udf
# Start ClickHouse with LangDB UDF
docker compose up -dai_completionsBasic example with system prompt:
-- Set system prompt
SET param_system_prompt = 'You are a helpful assistant. You will return only a single value sentiment score between 1 and 5 for every input and nothing else.';
-- Run completion
SELECT ai_completions
('{"model": "gpt-4o-mini", "max_tokens": 1000}')
({system_prompt:String}, 'You are very rude') as scoreYou can specify additional parameters like thread_id and run_id:
-- Set parameters
SET param_system_prompt = 'You are a helpful assistant. You will return only a single value sentiment score between 1 and 5 for every input and nothing else.';
-- Generate UUIDs for tracking
SELECT generateUUIDv4();
SET param_thread_id = '06b66882-e42e-4b17-ba93-4b5260a10ad8';
SET param_run_id = '06b66882-e42e-4b17-ba93-4b5260a10ad8';
-- Run completion with parameters
SELECT ai_completions
('{"model": "gpt-4o-mini", "max_tokens": 1000, "thread_id": "' || {thread_id:String} || '", "run_id": "' || {run_id:String} || '"}')
({system_prompt:String}, 'You are very rude') as scoreai_embedGenerate embeddings from text:
SELECT ai_embed
('{"model":"text-embedding-3-small"}')
('Life is beautiful') as embed_textThis example shows how to score HackerNews comments for harmful content:
-- Create and populate table
CREATE TABLE hackernews
ENGINE = MergeTree
ORDER BY id
SETTINGS allow_nullable_key = 1 EMPTY AS
SELECT *
FROM url('https://datasets-documentation.s3.eu-west-3.amazonaws.com/hackernews/hacknernews.parquet', 'Parquet');
-- Insert sample data
INSERT INTO hackernews SELECT *
FROM url('https://datasets-documentation.s3.eu-west-3.amazonaws.com/hackernews/hacknernews.parquet', 'Parquet')
LIMIT 100;
-- Set up parameters
SET param_system_prompt = 'You are a helpful assistant. You will return only a single value score between 1 and 5 for every input and nothing else based on malicious behavior. 0 being ok, 5 being the most harmful';
SET param_thread_id = '06b66882-e42e-4b17-ba93-4b5260a10ad8';
SET param_run_id = '06b66882-e42e-4b17-ba93-4b5260a10ad8';
-- Score content using multiple models
WITH tbl as ( select * from hackernews limit 5)
SELECT
id,
left(text, 100) as text_clip,
ai_completions
('{"model": "gpt-4o-mini", "max_tokens": 1000, "thread_id": "' || {thread_id:String} || '", "run_id": "' || {run_id:String} || '"}')
({system_prompt:String}, text) as gpt_4o_mini_score,
ai_completions
('{"model": "gemini/gemini-1.5-flash-8b", "max_tokens": 1000, "thread_id": "' || {thread_id:String} || '", "run_id": "' || {run_id:String} || '"}')
({system_prompt:String}, text) as gemini_15flash_score
FROM tbl
FORMAT PrettySpaceid text_clip gpt_4o_mini_score gemini_15flash_score
1. 7544833 This is a project for people who like to read and 2 2
2. 7544834 I appreciate your efforts to set the facts straigh 2 2
3. 7544835 Here in Western Europe, earning $100,000 per year 1 2
4. 7544836 Haha oh man so true. This is why I've found i 3 2
5. 7544837 The thing is it's gotten more attention from 1 2
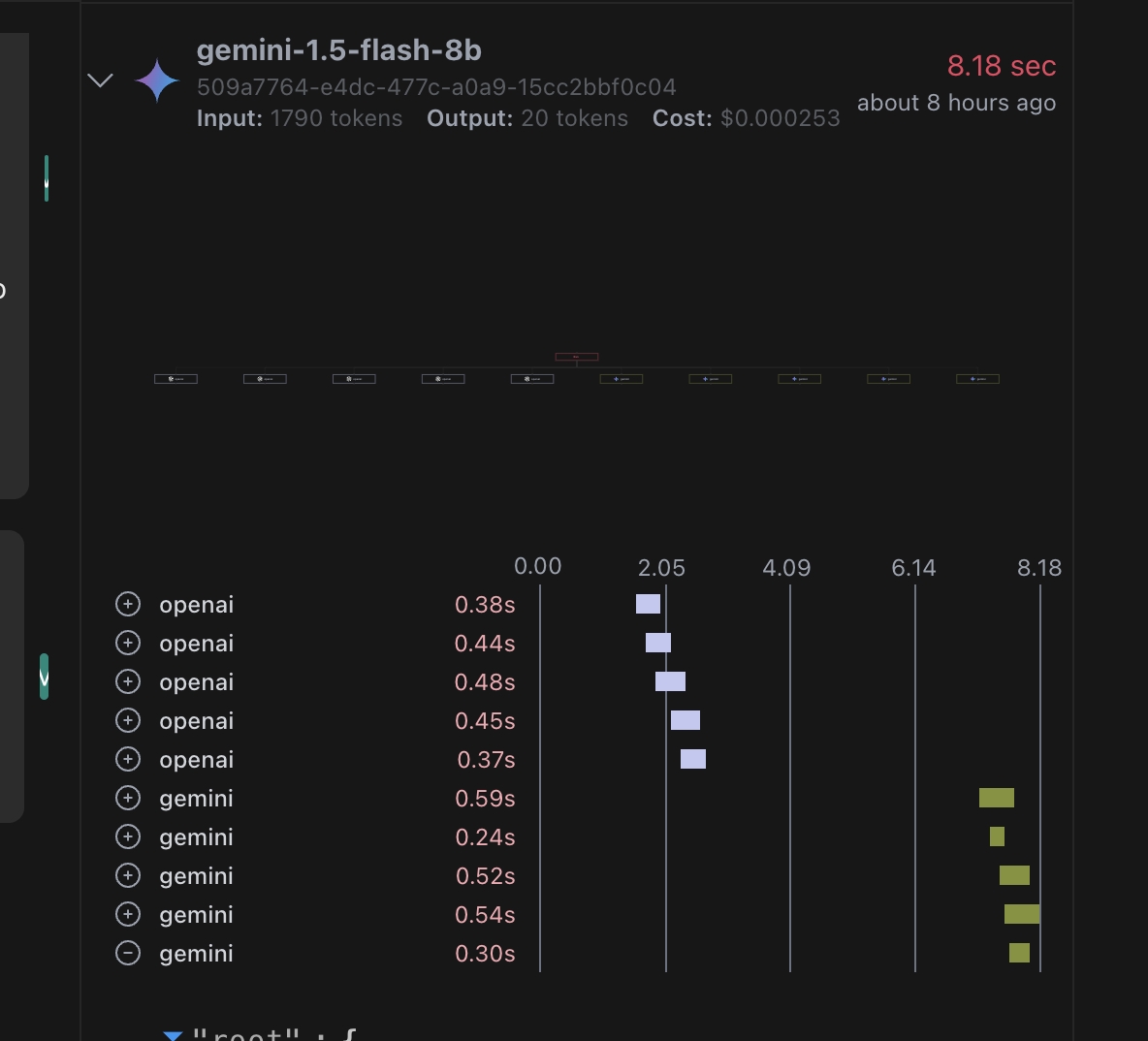
If tracing is enabled you ll be able to view several metrics about the request such as cost, time, Time to First Token etc on https://app.langdb.ai/
Returns the pricing details for LangDB services.
Successful retrieval of pricing information
GET /pricing HTTP/1.1
Host: api.us-east-1.langdb.ai
Accept: */*
Successful retrieval of pricing information
{
"model": "gpt-3.5-turbo-0125",
"provider": "openai",
"price": {
"per_input_token": 0.5,
"per_output_token": 1.5,
"valid_from": null
},
"input_formats": [
"text"
],
"output_formats": [
"text"
],
"capabilities": [
"tools"
],
"type": "completions",
"limits": {
"max_context_size": 16385
}
}LangDB project ID
Start time in microseconds.
1693062345678End time in microseconds.
1693082345678Successful response
Successful response
LangDB project ID
16930623456781693082345678["provider"]Successful response
Successful response
The ID of the thread to retrieve messages from
LangDB project ID
A list of messages for the given thread
A list of messages for the given thread
The ID of the thread for which to retrieve cost information
LangDB project ID
The total cost and token usage for the specified thread
The total cost and token usage for the specified thread
LangDB project ID
ID of the model to use. This can be either a specific model ID or a virtual model identifier.
gpt-4oSampling temperature.
0.8OK
OK
Creates an embedding vector representing the input text or token arrays.
ID of the model to use for generating embeddings.
text-embedding-ada-002The text to embed.
Array of text strings to embed.
The format to return the embeddings in.
floatPossible values: The number of dimensions the resulting embeddings should have.
1536Successful response with embeddings
Successful response with embeddings
POST /analytics HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 59
{
"start_time_us": 1693062345678,
"end_time_us": 1693082345678
}{
"timeseries": [
{
"hour": "2025-02-20 18:00:00",
"total_cost": 12.34,
"total_requests": 1000,
"avg_duration": 250.5,
"duration": 245.7,
"duration_p99": 750.2,
"duration_p95": 500.1,
"duration_p90": 400.8,
"duration_p50": 200.3,
"total_duration": 1,
"total_input_tokens": 1,
"total_output_tokens": 1,
"error_rate": 1,
"error_request_count": 1,
"avg_ttft": 1,
"ttft": 1,
"ttft_p99": 1,
"ttft_p95": 1,
"ttft_p90": 1,
"ttft_p50": 1,
"tps": 1,
"tps_p99": 1,
"tps_p95": 1,
"tps_p90": 1,
"tps_p50": 1,
"tpot": 0.85,
"tpot_p99": 1.5,
"tpot_p95": 1.2,
"tpot_p90": 1,
"tpot_p50": 0.75,
"tag_tuple": [
"text"
]
}
],
"start_time_us": 1,
"end_time_us": 1
}POST /analytics/summary HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 82
{
"start_time_us": 1693062345678,
"end_time_us": 1693082345678,
"groupBy": [
"provider"
]
}{
"summary": [
{
"tag_tuple": [
"openai",
"gpt-4"
],
"total_cost": 156.78,
"total_requests": 5000,
"total_duration": 1250000,
"avg_duration": 250,
"duration": 245.5,
"duration_p99": 750,
"duration_p95": 500,
"duration_p90": 400,
"duration_p50": 200,
"total_input_tokens": 100000,
"total_output_tokens": 50000,
"avg_ttft": 100,
"ttft": 98.5,
"ttft_p99": 300,
"ttft_p95": 200,
"ttft_p90": 150,
"ttft_p50": 80,
"tps": 10.5,
"tps_p99": 20,
"tps_p95": 15,
"tps_p90": 12,
"tps_p50": 8,
"tpot": 0.85,
"tpot_p99": 1.5,
"tpot_p95": 1.2,
"tpot_p90": 1,
"tpot_p50": 0.75,
"error_rate": 1,
"error_request_count": 1
}
],
"start_time_us": 1,
"end_time_us": 1
}POST /usage/total HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 47
{
"start_time_us": 1693062345678,
"end_time_us": 1
}{
"models": [
{
"provider": "openai",
"model_name": "gpt-4o",
"total_input_tokens": 3196182,
"total_output_tokens": 74096,
"total_cost": 10.4776979999,
"cost_per_input_token": 3,
"cost_per_output_token": 12
}
],
"total": {
"total_input_tokens": 4181386,
"total_output_tokens": 206547,
"total_cost": 11.8904386859
},
"period_start": 1737504000000000,
"period_end": 1740120949421000
}POST /threads HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 25
{
"limit": 10,
"offset": 100
}{
"data": [
{
"id": "123e4567-e89b-12d3-a456-426614174000",
"created_at": "2025-10-01T22:21:07.541Z",
"updated_at": "2025-10-01T22:21:07.541Z",
"model_name": "text",
"project_id": "text",
"score": 1,
"title": "text",
"user_id": "text"
}
],
"pagination": {
"limit": 10,
"offset": 100,
"total": 10
}
}GET /threads/{thread_id}/messages HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Accept: */*
[
{
"model_name": "gpt-4o-mini",
"thread_id": "123e4567-e89b-12d3-a456-426614174000",
"user_id": "langdb",
"content_type": "Text",
"content": "text",
"content_array": [
"text"
],
"type": "system",
"tool_call_id": "123e4567-e89b-12d3-a456-426614174000",
"tool_calls": "text",
"created_at": "2025-01-29 10:25:00.736000",
"id": "123e4567-e89b-12d3-a456-426614174000"
}
]GET /threads/{thread_id}/cost HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Accept: */*
{
"total_cost": 0.022226999999999997,
"total_output_tokens": 171,
"total_input_tokens": 6725
}POST /v1/chat/completions HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
X-Project-Id: text
Content-Type: application/json
Accept: */*
Content-Length: 599
{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
],
"temperature": 0.8,
"max_tokens": 1000,
"top_p": 0.9,
"frequency_penalty": 0.1,
"presence_penalty": 0.2,
"stream": false,
"response_format": "json_object",
"mcp_servers": [
{
"name": "websearch",
"type": "in-memory"
}
],
"router": {
"name": "kg_random_router",
"type": "script",
"script": "const route = ({ request, headers, models, metrics }) => { return {model: 'test'};};"
},
"extra": {
"guards": [
"word_count_validator_bd4bdnun",
"toxicity_detection_4yj4cdvu"
],
"user": {
"id": "7",
"name": "mrunmay",
"tags": [
"coding",
"software"
]
}
}
}{
"id": "text",
"choices": [
{
"finish_reason": "stop",
"index": 1,
"message": {
"role": "assistant",
"content": "text"
},
"logprobs": {
"content": [
{
"token": "text",
"logprob": 1
}
],
"refusal": [
{
"token": "text",
"logprob": 1
}
]
}
}
],
"created": 1,
"model": "text",
"service_tier": "scale",
"system_fingerprint": "text",
"object": "chat.completion",
"usage": {
"prompt_tokens": 1,
"completion_tokens": 1,
"total_tokens": 1,
"prompt_tokens_details": {
"cached_tokens": 1
},
"completion_tokens_details": {
"reasoning_tokens": 1,
"accepted_prediction_tokens": 1,
"rejected_prediction_tokens": 1
}
}
}POST /v1/embeddings HTTP/1.1
Host: api.us-east-1.langdb.ai
Authorization: Bearer YOUR_SECRET_TOKEN
Content-Type: application/json
Accept: */*
Content-Length: 136
{
"input": "The food was delicious and the waiter was kind.",
"model": "text-embedding-ada-002",
"encoding_format": "float",
"dimensions": 1536
}{
"data": [
{
"embedding": [
1
],
"index": 1
}
],
"model": "text",
"usage": {
"prompt_tokens": 1,
"total_tokens": 1
}
}